- Возможности объектов Index в pandas / pd 3
- Переиндексирование df.reindex()
- Удаление
- Арифметика и выравнивание данных
- Введение в pandas: анализ данных на Python
- DataFrame и Series
- Series
- DataFrame
- Доступ по индексу в DataFrame
- Чтение и запись данных
- Группировка и агрегирование в pandas
- Сводные таблицы в pandas
- Анализ временных рядов
- Визуализация данных в pandas
- Полезные ссылки
- 💌 Присоединяйтесь к рассылке
Возможности объектов Index в pandas / pd 3
В отличие от других структур данных в Python pandas не только пользуется преимуществами высокой производительности массивов NumPy, но и добавляет в них индексы.
Этот выбор оказался крайне удачным. Несмотря на и без того отличную гибкость, которая обеспечивается существующими динамическими структурами, внутренние ссылки на их элементы (а именно ими и являются метки) позволяют разработчикам еще сильнее упрощать операции.
В этом разделе речь пойдет о некоторых базовых функциях, использующих этот механизм:
- Переиндексирование
- Удаление
- Выравнивание
Переиндексирование df.reindex()
Вы уже знаете, что после объявления в структуре данных объект Index нельзя менять. Но с помощью операции переиндексирования это можно решить.
Существует даже возможность получить новую структуру из уже существующей, где правила индексирования заданы заново.
Для того чтобы провести переиндексирование объекта Series библиотека pandas предоставляет функцию reindex() . Она создает новый объект Series со значениями из другого Series , которые теперь переставлены в соответствии с новой последовательностью меток.
При операции переиндексирования можно поменять порядок индексов, удалить некоторые из них или добавить новые. Если метка новая, pandas добавит NaN на место соответствующего значения.
Как видно по выводу, порядок меток можно поменять полностью. Значение, которое раньше соответствовало метке two , удалено, зато есть новое с меткой five .
Тем не менее в случае, например, с большим Dataframe , не совсем удобно будет указывать новый список меток. Вместо этого можно использовать метод, который заполняет или интерполирует значения автоматически.
Для лучшего понимания механизма работы этого режима автоматического индексирования создадим следующий объект Series .
В этом примере видно, что колонка с индексами — это не идеальная последовательность чисел. Здесь пропущены цифры 1, 2 и 4. В таком случае нужно выполнить операцию интерполяции и получить полную последовательность чисел. Для этого можно использовать reindex с параметром method равным ffill . Более того, необходимо задать диапазон значений для индексов. Тут можно использовать range(6) в качестве аргумента.
Теперь в объекте есть элементы, которых не было в оригинальном объекте Series . Операция интерполяции сделала так, что наименьшие индексы стали значениями в объекте. Так, индексы 1 и 2 имеют значение 1, принадлежащее индексу 0.
Если нужно присваивать значения индексов при интерполяции, необходимо использовать метод bfill .
В этом случае значения индексов 1 и 2 равны 5, которое принадлежит индексу 3.
Операция отлично работает не только с Series , но и с Dataframe . Переиндексирование можно проводить не только на индексах (строках), но также и на колонках или на обоих. Как уже отмечалось, добавлять новые индексы и колонки возможно, но поскольку в оригинальной структуре есть недостающие значения, на их месте будет NaN .
| item | colors | price | new | object |
|---|---|---|---|---|
| id | ||||
| 0 | blue | 1.2 | blue | ball |
| 1 | green | 1.0 | green | pen |
| 2 | yellow | 3.3 | yellow | pencil |
| 3 | red | 0.9 | red | paper |
| 4 | white | 1.7 | white | mug |
Удаление
Еще одна операция, связанная с объектами Index — удаление. Удалить строку или колонку не составит труда, потому что метки используются для обозначения индексов и названий колонок.
В этом случае pandas предоставляет специальную функцию для этой операции, которая называется drop() . Метод возвращает новый объект без элементов, которые необходимо было удалить.
Например, возьмем в качестве примера случай, где из объекта нужно удалить один элемент. Для этого определим базовый объект Series из четырех элементов с 4 отдельными метками.
Теперь, предположим, необходимо удалить объект с меткой yellow . Для этого нужно всего лишь указать ее в качестве аргумента функции drop() .
Для удаления большего количества элементов, передайте массив с соответствующими индексами.
Если речь идет об объекте Dataframe , значения могут быть удалены с помощью ссылок на метки обеих осей. Возьмем в качестве примера следующий объект.
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
Для удаления строк просто передайте индексы строк.
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| white | 12 | 13 | 14 | 15 |
Для удаления колонок необходимо указывать индексы колонок, а также ось, с которой требуется удалить элементы. Для этого используется параметр axis . Чтобы сослаться на название колонки, нужно написать axis=1 .
| ball | paper | |
|---|---|---|
| red | 0 | 3 |
| blue | 4 | 7 |
| yellow | 8 | 11 |
| white | 12 | 15 |
Арифметика и выравнивание данных
Наверное, самая важная особенность индексов в этой структуре данных — тот факт, что pandas может выравнивать индексы двух разных структур. Это особенно важно при выполнении арифметических операций на их значениях. В этом случае индексы могут быть не только в разном порядке, но и присутствовать лишь в одной из двух структур.
В качестве примера можно взять два объекта Series с разными метками.
Теперь воспользуемся базовой операцией сложения. Как видно по примеру, некоторые метки есть в обоих структурах, а остальные — только в одной. Если они есть в обоих случаях, их значения складываются, а если только в одном — то значением будет NaN .
При использовании Dataframe выравнивание работает по тому же принципу, но проводится и для рядов, и для колонок.
Источник
Введение в pandas: анализ данных на Python
pandas это высокоуровневая Python библиотека для анализа данных. Почему я её называю высокоуровневой, потому что построена она поверх более низкоуровневой библиотеки NumPy (написана на Си), что является большим плюсом в производительности. В экосистеме Python, pandas является наиболее продвинутой и быстроразвивающейся библиотекой для обработки и анализа данных. В своей работе мне приходится пользоваться ею практически каждый день, поэтому я пишу эту краткую заметку для того, чтобы в будущем ссылаться к ней, если вдруг что-то забуду. Также надеюсь, что читателям блога заметка поможет в решении их собственных задач с помощью pandas, и послужит небольшим введением в возможности этой библиотеки.
DataFrame и Series
Чтобы эффективно работать с pandas, необходимо освоить самые главные структуры данных библиотеки: DataFrame и Series. Без понимания что они из себя представляют, невозможно в дальнейшем проводить качественный анализ.
Series
Структура/объект Series представляет из себя объект, похожий на одномерный массив (питоновский список, например), но отличительной его чертой является наличие ассоциированных меток, т.н. индексов, вдоль каждого элемента из списка. Такая особенность превращает его в ассоциативный массив или словарь в Python.
В строковом представлении объекта Series, индекс находится слева, а сам элемент справа. Если индекс явно не задан, то pandas автоматически создаёт RangeIndex от 0 до N-1, где N общее количество элементов. Также стоит обратить, что у Series есть тип хранимых элементов, в нашем случае это int64, т.к. мы передали целочисленные значения.
У объекта Series есть атрибуты через которые можно получить список элементов и индексы, это values и index соответственно.
Доступ к элементам объекта Series возможны по их индексу (вспоминается аналогия со словарем и доступом по ключу).
Индексы можно задавать явно:
Делать выборку по нескольким индексам и осуществлять групповое присваивание:
Фильтровать Series как душе заблагорассудится, а также применять математические операции и многое другое:
Если Series напоминает нам словарь, где ключом является индекс, а значением сам элемент, то можно сделать так:
У объекта Series и его индекса есть атрибут name, задающий имя объекту и индексу соответственно.
Индекс можно поменять «на лету», присвоив список атрибуту index объекта Series
Имейте в виду, что список с индексами по длине должен совпадать с количеством элементов в Series.
DataFrame
Объект DataFrame лучше всего представлять себе в виде обычной таблицы и это правильно, ведь DataFrame является табличной структурой данных. В любой таблице всегда присутствуют строки и столбцы. Столбцами в объекте DataFrame выступают объекты Series, строки которых являются их непосредственными элементами.
DataFrame проще всего сконструировать на примере питоновского словаря:
Чтобы убедиться, что столбец в DataFrame это Series, извлекаем любой:
Объект DataFrame имеет 2 индекса: по строкам и по столбцам. Если индекс по строкам явно не задан (например, колонка по которой нужно их строить), то pandas задаёт целочисленный индекс RangeIndex от 0 до N-1, где N это количество строк в таблице.
В таблице у нас 4 элемента от 0 до 3.
Доступ по индексу в DataFrame
Индекс по строкам можно задать разными способами, например, при формировании самого объекта DataFrame или «на лету»:
Как видно, индексу было задано имя — Country Code. Отмечу, что объекты Series из DataFrame будут иметь те же индексы, что и объект DataFrame:
Доступ к строкам по индексу возможен несколькими способами:
- .loc — используется для доступа по строковой метке
- .iloc — используется для доступа по числовому значению (начиная от 0)
Можно делать выборку по индексу и интересующим колонкам:
Как можно заметить, .loc в квадратных скобках принимает 2 аргумента: интересующий индекс, в том числе поддерживается слайсинг и колонки.
Фильтровать DataFrame с помощью т.н. булевых массивов:
Кстати, к столбцам можно обращаться, используя атрибут или нотацию словарей Python, т.е. df.population и df[‘population’] это одно и то же.
Сбросить индексы можно вот так:
pandas при операциях над DataFrame, возвращает новый объект DataFrame.
Добавим новый столбец, в котором население (в миллионах) поделим на площадь страны, получив тем самым плотность:
Не нравится новый столбец? Не проблема, удалим его:
Особо ленивые могут просто написать del df[‘density’].
Переименовывать столбцы нужно через метод rename:
В этом примере перед тем как переименовать столбец Country Code, убедитесь, что с него сброшен индекс, иначе не будет никакого эффекта.
Чтение и запись данных
pandas поддерживает все самые популярные форматы хранения данных: csv, excel, sql, буфер обмена, html и многое другое:
Чаще всего приходится работать с csv-файлами. Например, чтобы сохранить наш DataFrame со странами, достаточно написать:
Функции to_csv ещё передаются различные аргументы (например, символ разделителя между колонками) о которых подробнее можно узнать в официальной документации.
Считать данные из csv-файла и превратить в DataFrame можно функцией read_csv.
Аргумент sep указывает разделитесь столбцов. Существует ещё масса способов сформировать DataFrame из различных источников, но наиболее часто используют CSV, Excel и SQL. Например, с помощью функции read_sql, pandas может выполнить SQL запрос и на основе ответа от базы данных сформировать необходимый DataFrame. За более подробной информацией стоит обратиться к официальной документации.
Группировка и агрегирование в pandas
Группировка данных один из самых часто используемых методов при анализе данных. В pandas за группировку отвечает метод .groupby. Я долго думал какой пример будет наиболее наглядным, чтобы продемонстрировать группировку, решил взять стандартный набор данных (dataset), использующийся во всех курсах про анализ данных — данные о пассажирах Титаника. Скачать CSV файл можно тут.
Необходимо подсчитать, сколько женщин и мужчин выжило, а сколько нет. В этом нам поможет метод .groupby.
А теперь проанализируем в разрезе класса кабины:
Сводные таблицы в pandas
Термин «сводная таблица» хорошо известен тем, кто не по наслышке знаком с инструментом Microsoft Excel или любым иным, предназначенным для обработки и анализа данных. В pandas сводные таблицы строятся через метод .pivot_table. За основу возьмём всё тот же пример с Титаником. Например, перед нами стоит задача посчитать сколько всего женщин и мужчин было в конкретном классе корабля:
В качестве индекса теперь у нас будет пол человека, колонками станут значения из PClass, функцией агрегирования будет count (подсчёт количества записей) по колонке Name.
Всё очень просто.
Анализ временных рядов
В pandas очень удобно анализировать временные ряды. В качестве показательного примера я буду использовать цену на акции корпорации Apple за 5 лет по дням. Файл с данными можно скачать тут.
Здесь мы формируем DataFrame с DatetimeIndex по колонке Date и сортируем новый индекс в правильном порядке для работы с выборками. Если колонка имеет формат даты и времени отличный от ISO8601, то для правильного перевода строки в нужный тип, можно использовать метод pandas.to_datetime.
Давайте теперь узнаем среднюю цену акции (mean) на закрытии (Close):
А если взять промежуток с февраля 2012 по февраль 2015 и посчитать среднее:
А что если нам нужно узнать среднюю цену закрытия по неделям?!
Resampling мощный инструмент при работе с временными рядами (time series), помогающий переформировать выборку так, как удобно вам. Метод resample первым аргументом принимает строку rule. Все доступные значения можно найти в документации.
Визуализация данных в pandas
Для визуального анализа данных, pandas использует библиотеку matplotlib. Продемонстрирую простейший способ визуализации в pandas на примере с акциями Apple.
Берём цену закрытия в промежутке между 2012 и 2017.
И видим вот такую картину:
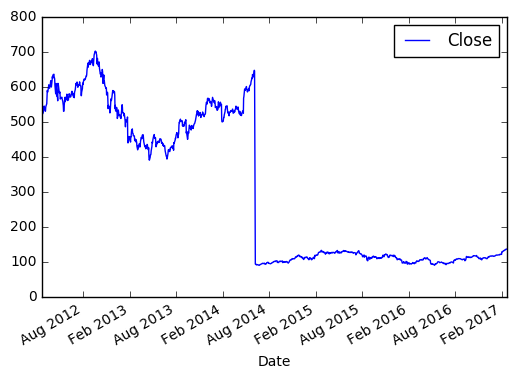
По оси X, если не задано явно, всегда будет индекс. По оси Y в нашем случае цена закрытия. Если внимательно посмотреть, то в 2014 году цена на акцию резко упала, это событие было связано с тем, что Apple проводила сплит 7 к 1. Так мало кода и уже более-менее наглядный анализ 😉
Эта заметка демонстрирует лишь малую часть возможностей pandas. Со своей стороны я постараюсь по мере своих сил обновлять и дополнять её.
Полезные ссылки
💌 Присоединяйтесь к рассылке
Понравился контент? Пожалуйста, подпишись на рассылку.
Источник







