- numpy.unique
- Множества (unique) и операции над ними
- Операции над множествами
- Пересечение множеств
- Объединение множеств
- Вычитание множеств
- Симметричная разность (XOR)
- Видео по теме
- Изучаем Python: поиск в списке
- Способы получения уникальных значений из списка в Python
- 1. Set()
- 2. Python list.append() и цикл for
- 3. Метод numpy.unique() для создания списка с уникальными элементами
- Заключение
- numpy.unique¶
- 6 Способов в Python подсчитать уникальные значения в списке
- Вступление
- Уникальный элемент Python в списке
- Различные методы подсчета уникальных значений
- 1. Python Подсчитывает уникальные значения в списке обычным методом грубой силы
- 2. С помощью счетчика
- 3. Python Подсчитывает Уникальные Значения В Списке С помощью набора
- 4. С помощью numpy.unique
- 5. Python Подсчитывает Уникальные Значения В Списке С Помощью Функции pandas dict + zip
- 6. Использование фрейма данных pandas.
- Кроме того, Читайте
- Вывод
numpy.unique
Функция unique() находит уникальные элементы массива и возвращает их в отсортированном массиве.
В зависимости от установленных параметров, данная функция может возвращать: индексы входного массива, которые соответствуют его уникальным элементам; индексы уникального массива, которые позволяют восстановить входной массив; количество вхождений каждого уникального элемента во входном массиве.
Параметры: a — подобный массиву объект Массив NumPy или любой объект который может быть преобразован в массив NumPy. Если входной массив не является одномерным и не указана ось, по которой необходимо искать ункальные элементы, то данный массив будет сжат до одной оси. return_index — True или False (необязательный) Если True то помимо самих уникальных элементов так же будут возвращаться их индексы во входном массиве. По умолчанию return_index = False . return_inverse — True или False (необязательный) Если True то помимо самих уникальных элементов так же будут возвращаться индексы уникального массива, которые можно использовать для восстановления входного массива. По умолчанию return_inverse = False . return_counts — True или False (необязательный) Если True то помимо самих уникальных элементов так же будет возвращаться количество вхождений каждого из них во входном массиве. По умолчанию return_counts = False . axis — целое число или None (необязательный) Определяет ось по которой необходимо найти уникальные элементы. Если axis = None (по умолчанию), то входной массив будет сжат до одной оси. Если ось указана, то повторяющиеся элементы вдоль оси будут удалены, а все остальные оси будут принадлежать каждому из уникальных элементов. Массивы объектов (массивов из других массивов NumPy или их подклассов) и структурированные массивы не обрабатываются если не указанна ось. Подмассивы и элементы структурированного массива сортируются в лексикографическом порядке. Возвращает: Массив уникальных элементов Одномерный отсортированный ммассив NumPy, который состоит из уникальных элементов входного массива. Массив индексов уникальных элементов (если return_index = True ) Одномерный ммассив NumPy, который состоит из индексов первых вхождений уникальных элементов. Массив индексов уникальных элементов (если return_inverse = True ) Одномерный ммассив NumPy, который состоит из индексов всех вхождений уникальных элементов, пригодный для восстановления исходного массива. Массив с количеством вхождений уникальных элементов (если return_counts = True ) Одномерный ммассив NumPy, который состоит из чисел соответствующих количеству вхождений каждого уникального элемента в исходном массиве.
Источник
Множества (unique) и операции над ними
На этом занятии познакомимся с еще одним типом математических операций пакета NumPy – работы со множествами. И ответим на первый вопрос: что такое множество с позиции NumPy? Смотрите, предположим имеется одномерный массив:
В нем есть неуникальные (повторяющиеся) значения. Так вот, в множествах все значения должны быть уникальными и представленными в единственном варианте. Чтобы преобразовать массив a в множество используется функция unique:
В действительности, это такой же массив, только с уникальными значениями.
У функции unique есть несколько полезных параметров. Первый из них return_counts:
который позволяет возвращать не только уникальные значения, но и число их вхождений в исходном массиве a.
Следующий параметр return_index позволяет определять индексы первого вхождения уникальных элементов в исходном массиве:
Наконец, третий параметр return_inverse возвращает индексы, по которым можно точно восстановить исходный массив. Понять этот параметр проще всего на примере:
на выходе получим:
(array([1, 2, 3, 4]), array([0, 1, 2, 3, 3, 2, 1, 0], dtype=int32))
Видите, здесь 1 у множества имеет индекс 0 и во втором массиве стоят нули там, где должна быть 1. И так для всех значений. Далее, по этой информации можно выполнить восстановление исходного массива a. Делается это так:
Подробнее о таком списочном индексировании мы поговорим на следующем занятии.
Функция unique также может работать и с многомерными массивами. Например:
То есть, она просматривает весь массив x и оставляет только уникальные значения. На выходе формируется обычный одномерный массив.
Однако, здесь мы можем дополнительно указывать оси, по которым будет происходить отбор уникальных значений, например, так:
array([[0, 1, 1, 2],
[9, 1, 1, 2]])
Здесь использовалась первая ось, то есть, определялись уникальные строки. Если указать вторую ось:
то получим уникальные столбцы:
Операции над множествами
В NumPy есть несколько функций для выполнения базовых операций с множествами. Первая – это проверка вхождений элементов одного множества в другое. Например, заданы два массива с уникальными значениями (множества):
И выполним функцию in1d:
На выходе получим массив булевых значений и там где стоит False означает отсутствие элемента, а там где стоит True – наличие совпадения. Причем, порядок следования элементов не имеет никакого значения. Если перемешать массив y:
то видим тот же результат.
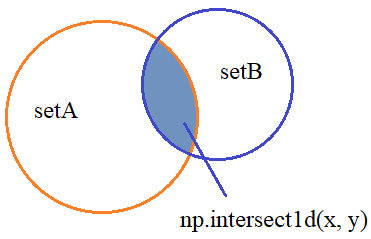
Пересечение множеств
Следующая базовая операция – это пересечение двух множеств, то есть, определение значений, которые входят в оба множества одновременно. Она выполняется с помощью функции:
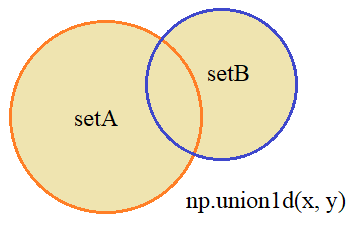
Объединение множеств
Противоположная ей операция – объединение множеств, реализуется с помощью функции:
Соответственно, получим уникальные числа, которые входят в оба множества:
Вычитание множеств
Далее, множества можно вычитать друг из друга, причем результат будет зависеть от того, какое множество из какого вычитается:
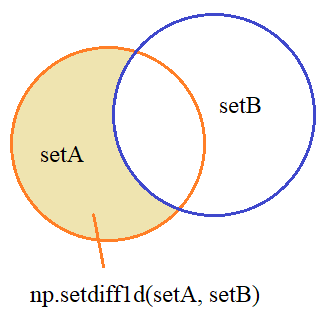
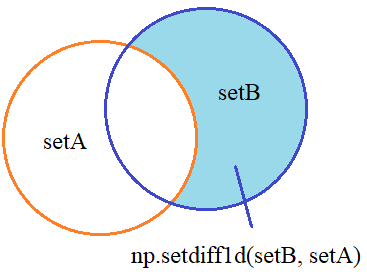
Реализуются эти операции с помощью функции setdiff1d:
Симметричная разность (XOR)
Последняя базовая операция – это вычисление симметричной разности, то есть, остаются не совпадающие значения из двух множеств:
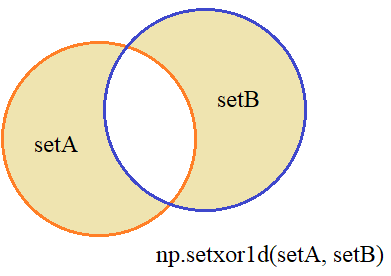
Реализуется это с помощью функции setxor1d:
Вот так, с помощью пакета NumPy, можно работать с одномерными массивами, состоящих из уникальных значений и выполнять над ними операции как с множествами.
Видео по теме

#1. Пакет numpy — установка и первое знакомство | NumPy уроки

#2. Основные типы данных. Создание массивов функцией array() | NumPy уроки

#3. Функции автозаполнения, создания матриц и числовых диапазонов | NumPy уроки

#4. Свойства и представления массивов, создание их копий | NumPy уроки

#5. Изменение формы массивов, добавление и удаление осей | NumPy уроки

#6. Объединение и разделение массивов | NumPy уроки

#7. Индексация, срезы, итерирование массивов | NumPy уроки

#8. Базовые математические операции над массивами | NumPy уроки

#9. Булевы операции и функции, значения inf и nan | NumPy уроки

#10. Базовые математические функции | NumPy уроки

#11. Произведение матриц и векторов, элементы линейной алгебры | NumPy уроки

#12. Множества (unique) и операции над ними | NumPy уроки

#13. Транслирование массивов | NumPy уроки
© 2021 Частичное или полное копирование информации с данного сайта для распространения на других ресурсах, в том числе и бумажных, строго запрещено. Все тексты и изображения являются собственностью сайта
Источник
Изучаем Python: поиск в списке
В этой статье мы рассмотрим три способа получения уникальных значений из списка Python .
Способы получения уникальных значений из списка в Python
Уникальные значения из списка можно извлечь с помощью:
- Метода Python set().
- Метода list.append() вместе с циклом for.
- Метода numpy.unique().
1. Set()
- Сначала нужно преобразовать список в набор с помощью функции set().
Поскольку список преобразуется в набор, в него помещается только одна копия всех элементов.
- Затем преобразуем набор обратно в список, используя следующую команду:
2. Python list.append() и цикл for
Чтобы найти уникальные элементы, используем цикл for вместе с функцией list.append().
- Создадим новый список res_list.
- С помощью цикла for проверяем наличие определенного элемента в созданном списке (res_list). Если элемент отсутствует, он добавляется в новый список с помощью метода append().
Если во время переборки мы сталкиваемся с элементом, который уже существует в новом списке, то он игнорируется циклом for. Используем оператор if, чтобы проверить, является ли элемент уникальным или копией.
3. Метод numpy.unique() для создания списка с уникальными элементами
Модуль Python NumPy включает в себя встроенную функцию numpy.unique, предназначенную для извлечения уникальных элементов из массива.
- Сначала преобразуем список в массив NumPy, используя приведенную ниже команду.
Далее используем метод numpy.unique() для извлечения уникальных элементов данных из массива numpy.
- Выводим на экран полученный список.
Заключение
В этой статье мы рассмотрели три способа извлечения уникальных значений из списка Python.
Пожалуйста, опубликуйте свои отзывы по текущей теме статьи. За комментарии, подписки, дизлайки, лайки, отклики низкий вам поклон!
Источник
numpy.unique¶
Find the unique elements of an array.
Returns the sorted unique elements of an array. There are three optional outputs in addition to the unique elements:
the indices of the input array that give the unique values
the indices of the unique array that reconstruct the input array
the number of times each unique value comes up in the input array
Parameters ar array_like
Input array. Unless axis is specified, this will be flattened if it is not already 1-D.
return_index bool, optional
If True, also return the indices of ar (along the specified axis, if provided, or in the flattened array) that result in the unique array.
return_inverse bool, optional
If True, also return the indices of the unique array (for the specified axis, if provided) that can be used to reconstruct ar.
return_counts bool, optional
If True, also return the number of times each unique item appears in ar.
New in version 1.9.0.
The axis to operate on. If None, ar will be flattened. If an integer, the subarrays indexed by the given axis will be flattened and treated as the elements of a 1-D array with the dimension of the given axis, see the notes for more details. Object arrays or structured arrays that contain objects are not supported if the axis kwarg is used. The default is None.
New in version 1.13.0.
The sorted unique values.
unique_indices ndarray, optional
The indices of the first occurrences of the unique values in the original array. Only provided if return_index is True.
unique_inverse ndarray, optional
The indices to reconstruct the original array from the unique array. Only provided if return_inverse is True.
unique_counts ndarray, optional
The number of times each of the unique values comes up in the original array. Only provided if return_counts is True.
New in version 1.9.0.
Module with a number of other functions for performing set operations on arrays.
Repeat elements of an array.
When an axis is specified the subarrays indexed by the axis are sorted. This is done by making the specified axis the first dimension of the array (move the axis to the first dimension to keep the order of the other axes) and then flattening the subarrays in C order. The flattened subarrays are then viewed as a structured type with each element given a label, with the effect that we end up with a 1-D array of structured types that can be treated in the same way as any other 1-D array. The result is that the flattened subarrays are sorted in lexicographic order starting with the first element.
Return the unique rows of a 2D array
Return the indices of the original array that give the unique values:
Reconstruct the input array from the unique values and inverse:
Reconstruct the input values from the unique values and counts:
© Copyright 2008-2021, The NumPy community.
Last updated on Jun 22, 2021.
Created using Sphinx 4.0.1.
Источник
6 Способов в Python подсчитать уникальные значения в списке
Значения, которые появляются в списке только один раз, являются уникальными. Мы обсудим различные методы подсчета уникальных значений python в списке.
Автор: Team Python Pool
Дата записи
Вступление
В Python у нас есть дубликаты элементов, присутствующих в списке. Иногда мы сталкиваемся с ситуацией, когда нам нужно подсчитать уникальные значения в списке в Python. Поэтому мы будем обсуждать различные способы поиска уникальных значений в массиве или списке. А также выведите количество уникальных элементов, присутствующих в списке.
Уникальный элемент Python в списке
Уникальные элементы-это элементы, которые появляются только один раз в списке .
Предположим, у нас есть список = [1, 2, 3, 2, 3, 5, 1, 6, 1]. Здесь мы видим, что 1 приходит 3 раза, 2 приходит 2 раза, 3 приходит 2 раза, 5 и 6 приходят один раз. Если мы посчитаем уникальные элементы в списке, то их будет всего 5.[1, 2, 3, 5, 6].
Различные методы подсчета уникальных значений
Давайте разберемся во всех различных методах, с помощью которых мы можем вычислить количество уникальных элементов в списке или массиве с помощью примеров:
1. Python Подсчитывает уникальные значения в списке обычным методом грубой силы
Мы называем этот метод подходом грубой силы . Этот метод не так эффективен, так как в нем больше времени и больше пространства. Этот подход будет принимать пустой список и переменную count, которая будет установлена в 0. мы пройдем от начала до конца и проверим, нет ли этого значения в пустом списке. Затем мы добавим его и увеличим переменную count на 1. Если его нет в пустом списке, то мы не будем его считать, не будем добавлять в пустой список.
Здесь, во-первых, мы взяли входной список и напечатали входной список. Во-вторых, мы взяли пустой список и переменную count, которая установлена в 0. В-третьих, мы прошли список с самого начала и проверили, нет ли значения в пустом списке или нет. Если значение отсутствует в пустом списке, мы увеличиваем значение счетчика на 1 и добавляем это значение в пустой список. Если мы обнаруживаем, что элементы присутствуют в списке, мы не добавляем их в пустой список и не увеличиваем значение счетчика на 1. Наконец, мы напечатали пустой список, который теперь содержит уникальные значения и количество списка. Таким образом, мы можем видеть все уникальные элементы в списке.
2. С помощью счетчика
В этом методе мы будем использовать функцию счетчика из библиотеки коллекций. В этом случае мы будем создавать словарь с помощью функции counter (). Ключи будут уникальными элементами, а значения-числом этого уникального элемента. Взяв ключи из словаря, мы создадим список и напечатаем длину списка.
Выход:
Здесь, во-первых, мы импортировали функцию Counter() из библиотеки коллекций. Во-вторых, мы взяли входной список и напечатали входной список. В-третьих, мы применили счетчик(), неупорядоченную коллекцию, где элементы хранятся как ключи словаря, а их подсчеты хранятся как значения словаря. Из входного списка мы создали новый список, в котором хранятся только те элементы, ключевые значения которых присутствуют один раз. Все эти элементы различны в списке. Наконец, мы напечатали пустой список, который теперь содержит уникальные значения и количество списка. Таким образом, мы можем видеть все уникальные элементы в списке.
3. Python Подсчитывает Уникальные Значения В Списке С помощью набора
В этом методе мы будем использовать встроенный тип данных python, называемый Set. Мы возьмем входные данные в виде списка, а затем преобразуем их в набор. Как мы все знаем, набор не содержит в себе никаких повторяющихся элементов. Он будет содержать только уникальные элементы, и мы выведем длину списка с помощью функции length ().
Здесь, во-первых, мы взяли входной список и напечатали входной список. Во-вторых, мы преобразовали входной список в набор. Set, который является встроенным типом данных в python, содержит только уникальные элементы в нем. В-третьих, мы сохранили все значения в другом списке. Наконец, мы напечатали пустой список, который теперь содержит уникальные значения и количество списка. Таким образом, мы можем видеть все уникальные элементы в списке.
4. С помощью numpy.unique
В этом методе мы импортируем библиотеку numpy с ее псевдонимом np. В библиотеке numpy мы будем использовать функцию numpy.unique (), которая возвращает уникальное значение входного списка. Мы также можем вернуть количество каждого уникального значения, если параметр return count имеет значение True.
Здесь, во-первых, мы импортировали модуль numpy в качестве псевдонима np. Во-вторых, мы взяли входной список и напечатали входной список. В-третьих, мы применили numpy. unique (), который сохранит только уникальные значения списка и сохранит их в другом списке. Наконец, мы напечатали пустой список, который теперь содержит уникальные значения и количество списка. Таким образом, мы можем видеть все уникальные элементы в списке.
5. Python Подсчитывает Уникальные Значения В Списке С Помощью Функции pandas dict + zip
В этом методе мы будем использовать словарь с комбинацией функций zip для поиска уникальных значений строки путем преобразования их в список.
Здесь во-первых, мы взяли строку как. Во-вторых, мы применили функцию dict внутри того, что мы применили функцию zip, и внутри нее мы преобразовали строку в список и подсчитали ключи и значения, пройдя по списку. В-третьих, мы взяли переменную unique, в которой мы хранили ключи и значения словаря. Наконец, мы напечатали длину словаря с помощью функции length в python.
6. Использование фрейма данных pandas.
В этом методе мы будем импортировать панд в качестве псевдонима pd. мы будем принимать входные данные в кадре данных панд.
Здесь, во-первых, мы импортировали модуль панд с псевдонимом pd. Во – вторых, мы создали фрейм данных с вводом меток и имен. В-третьих, мы создали переменную n, в которой будем хранить значение. Мы применили уникальную функцию в метках в панд, а затем вычислили ее длину с помощью функции длины и сохранили ее в переменной n. Наконец-то мы напечатали результат.
Кроме того, Читайте
- Numpy Count | Практическое объяснение поиска вхождений
- 4 Надежных Способа Подсчета Слов в строке в Python
- 5 Лучших способов найти длину строки Python
- Использование панд в CSV() с совершенством
- Сложение матриц в Python | Сложение двух матриц
Вывод
В этом уроке мы увидели, что представляют собой уникальные элементы в списке. Кроме того, мы видели различные методы, с помощью которых мы можем найти уникальные элементы в списке. Мы также подсчитали уникальные элементы в списке и напечатали их количество. Все методы подробно объясняются с помощью примеров. Все примеры также объясняются, что даст вам лучшее понимание методов. Вы можете использовать любую из программ, чтобы найти количество уникальных элементов в списке в соответствии с вашими потребностями и выбором.
Источник







