- Нескучный Pandas: выбор строк и столбцов одновременно в .iloc
- Здесь про это:
- Резюме по .loc и .iloc
- Как выбрать строки из Pandas DataFrame по условию
- Синтаксис выборки строк из Pandas DataFrame по условию
- Выберем строки, где цена равна или больше 10
- Выберем строки, в которых цвет зеленый, а форма — прямоугольник
- Выберем строки, где цвет зеленый ИЛИ форма прямоугольная
- Выберем строки, где цена не равна 15
- Опубликовано Вадим В. Костерин
- Как перебирать строки в фрейме данных Pandas
- Итерация DataFrames с помощью items()
- Итерация DataFrames с помощью iterrows()
- Итерация DataFrames с помощью itertuples()
- Производительность итерации с помощью Pandas
- Сравнение скорости
- Вывод
- Как вывести выборку строк в pandas
- 1 ответ 1
- Моя шпаргалка по pandas
- 1. Подготовка к работе
- 2. Импорт данных
- ▍Загрузка CSV-данных
- ▍Создание датафрейма из данных, введённых вручную
- ▍Копирование датафрейма
- 3. Экспорт данных
- ▍Экспорт в формат CSV
- 4. Просмотр и исследование данных
- ▍Получение n записей из начала или конца датафрейма
- ▍Подсчёт количества строк в датафрейме
- ▍Подсчёт количества уникальных значений в столбце
- ▍Получение сведений о датафрейме
- ▍Вывод статистических сведений о датафрейме
- ▍Подсчёт количества значений
- 5. Извлечение информации из датафреймов
- ▍Создание списка или объекта Series на основе значений столбца
- ▍Получение списка значений из индекса
- ▍Получение списка значений столбцов
- 6. Добавление данных в датафрейм и удаление их из него
- ▍Присоединение к датафрейму нового столбца с заданным значением
- ▍Создание нового датафрейма из подмножества столбцов
- ▍Удаление заданных столбцов
- ▍Добавление в датафрейм строки с суммой значений из других строк
- 7. Комбинирование датафреймов
- ▍Конкатенация двух датафреймов
- ▍Слияние датафреймов
- 8. Фильтрация
- ▍Получение строк с нужными индексными значениями
- ▍Получение строк по числовым индексам
- ▍Получение строк по заданным значениям столбцов
- ▍Получение среза датафрейма
- ▍Фильтрация по значению
- 9. Сортировка
- 10. Агрегирование
- ▍Функция df.groupby и подсчёт количества записей
- ▍Функция df.groupby и агрегирование столбцов различными способами
- ▍Создание сводной таблицы
- 11. Очистка данных
- ▍Запись в ячейки, содержащие значение NaN, какого-то другого значения
- 12. Другие полезные возможности
- ▍Отбор случайных образцов из набора данных
- ▍Перебор строк датафрейма
- ▍Борьба с ошибкой IOPub data rate exceeded
- Итоги
Нескучный Pandas: выбор строк и столбцов одновременно в .iloc
Здесь про это:
Рассмотрим несколько примеров, чтобы понять, чем отличается .iloc от .loc.
Выберем две строки и два столбца:
Осуществим выборку строк и столбцов с помощью среза:
Выберем 1 значение из столбца и указанной колонки:
Результат:
Резюме по .loc и .iloc
Доступ к строкам и колонкам по индексу возможен несколькими способами:
- .loc — используется для доступа по строковой метке — т.е. фактически по значению индекса и по названию столбца
- .iloc — используется для доступа по числовому значению (начиная от 0) — т.е. по номеру строки и номеру столбца



Как выбрать строки из Pandas DataFrame по условию
Собираем тестовый набор данных для иллюстрации работы выборки по условию
| Color | Shape | Price |
| Green | Rectangle | 10 |
| Green | Rectangle | 15 |
| Green | Square | 5 |
| Blue | Rectangle | 5 |
| Blue | Square | 10 |
| Red | Square | 15 |
| Red | Square | 15 |
| Red | Rectangle | 5 |
Пишем скрипт:
Синтаксис выборки строк из Pandas DataFrame по условию
Вы можете использовать следующую логику для выбора строк в Pandas DataFrame по условию:
Например, если вы хотите получить строки с зеленым цветом , вам нужно применить:
- Color — это название столбца
- Green — это условие (значение колонки)
А вот полный код Python для нашего примера:
Результат:
Выберем строки, где цена равна или больше 10
Чтобы получить все строки, где цена равна или больше 10, Вам нужно применить следующее условие:
Полный код Python:
Результат:
Выберем строки, в которых цвет зеленый, а форма — прямоугольник
Теперь цель состоит в том, чтобы выбрать строки на основе двух условий:
- Color зеленый; а также
- Shape = прямоугольник
Мы будем использовать символ & для применения нескольких условий. В нашем примере код будет выглядеть так:
Полный код примера Python для выборки Pandas DataFrame:
Результат:
Выберем строки, где цвет зеленый ИЛИ форма прямоугольная
Для достижения этой цели будем использовать символ | следующим образом:
Полный код Python 3:
Выберем строки, где цена не равна 15
Мы будем использовать комбинацию символов !=, чтобы выбрать строки, цена которых не равна 15:
Полный код Pandas DF на питоне:
Результат работы скрипта Python:
Опубликовано Вадим В. Костерин
ст. преп. кафедры ЦЭиИТ. Автор более 130 научных и учебно-методических работ. Лауреат ВДНХ (серебряная медаль). Посмотреть больше записей
Источник
Как перебирать строки в фрейме данных Pandas

Pandas — чрезвычайно популярный фреймворк для обработки данных в Python. Во многих случаях вам может потребоваться перебрать данные — либо для их распечатки, либо для выполнения с ними некоторых операций.
В этом руководстве мы рассмотрим, как перебирать строки в Pandas DataFrame .
Давайте рассмотрим три основных способа перебора DataFrame:
Итерация DataFrames с помощью items()
Давайте настроим некоторые данные о вымышленных людях в DataFrame :
Обратите внимание, что мы используем id как наш индекс DataFrame . Давайте посмотрим, как выглядит этот DataFrame :
Теперь, чтобы перебрать этот DataFrame , мы воспользуемся функцией items() :
Он возвращает генератор:
Мы можем использовать это для генерации пар col_name и data . Эти пары будут содержать имя столбца и каждую строку данных для этого столбца. Давайте пройдемся по именам столбцов и их данным:
Мы успешно перебрали все строки в каждом столбце. Обратите внимание, что столбец индекса остается неизменным на протяжении итерации, поскольку это связанный индекс для значений. Если вы не определяете индекс, Pandas соответствующим образом пронумеровывает столбец индекса.
Мы также можем напечатать конкретную строку, передав номер индекса в data , как мы это делаем со списками Python:
Обратите внимание, что индекс списка начинается с нуля, поэтому data[1] будет относиться ко второй строке. Вы увидите этот вывод:
Мы также можем передать значение индекса в data .
Результат будет таким же, как и раньше:
Итерация DataFrames с помощью iterrows()
В то время как df.items() перебирает строки по столбцам, выполняя цикл для каждого столбца, мы можем использовать iterrows() , чтобы получить все строковые данные индекса.
Попробуем перебрать строки с помощью iterrows() :
В цикле for i представляет столбец индекса (наш DataFrame имеет индексы от id001 до id006 ) и row содержит данные для этого индекса во всех столбцах. Наш результат будет выглядеть так:
Точно так же мы можем перебирать строки в определенном столбце. Просто передав номер индекса или имя столбца в row . Например, мы можем выборочно распечатать первый столбец строки следующим образом:
Оба они производят такой вывод:
Итерация DataFrames с помощью itertuples()
Функция itertuples() также возвращает генератор, который генерирует значение строк в кортежах. Давайте попробуем это:
Вы увидите это в своей оболочке Python:
У метода itertuples() два аргумента: index и name .
Мы можем не отображать столбец индекса, установив для параметра index значение False :
У наших кортежей больше не будет отображаться индекс:
Как вы уже заметили, этот генератор выдает именованные кортежи с именем по умолчанию Pandas . Мы можем изменить это, передав People аргумент параметру name . Вы можете выбрать любое имя, которое вам нравится, но всегда лучше выбирать имена, соответствующие вашим данным:
Теперь наш вывод будет:
Производительность итерации с помощью Pandas
Официальная документация Pandas предупреждает, что итерационный процесс медленный. Если вы выполняете итерацию, чтобы изменить данные DataFrame , векторизация была бы более быстрой альтернативой. Кроме того, не рекомендуется изменять данные во время итерации по строкам, поскольку Pandas иногда возвращает копию данных в строке, а не ссылку на нее, что означает, что не все данные будут фактически изменены.
Для небольших наборов данных вы можете использовать этот метод to_string() для отображения всех данных. Для больших наборов данных, содержащих много столбцов и строк, вы можете использовать методы head(n) или tail(n) для печати первых n строк вашего DataFrame (значение по умолчанию n — 5).
Сравнение скорости
Чтобы измерить скорость каждого конкретного метода, мы обернули их в функции, которые будут выполнять их 1000 раз и возвращать среднее время выполнения.
Чтобы проверить эти методы, мы будем использовать обе функции print() и list.append() , чтобы обеспечить более точные данные сравнения и для покрытия общих случаев использования. Чтобы определить справедливого победителя, мы будем перебирать DataFrame и использовать только одно значение для печати или добавления в цикл.
Вот как выглядят возвращаемые значения для каждого метода:
Например, при items() :
iterrows() предоставит все данные столбца для конкретной строки:
И, наконец, одна строка для элемента itertuples() будет выглядеть так:
Вот средние результаты в секундах:
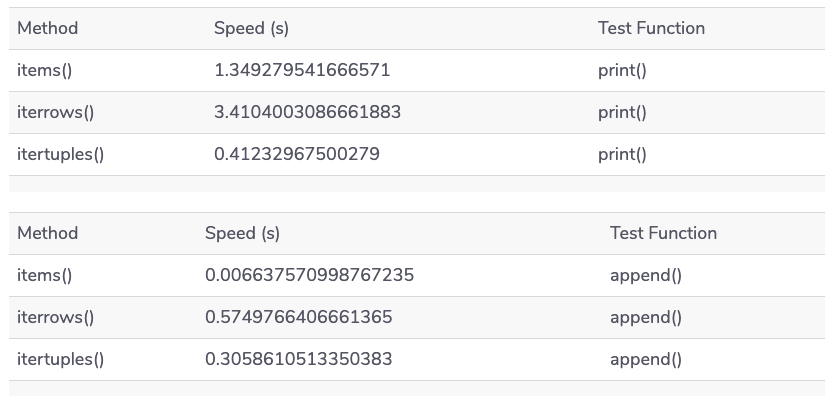
Печать значений потребует больше времени и ресурсов, чем добавление в целом, и наши примеры не являются исключением. Хотя метод itertuples() работает лучше в сочетании с print() , метод items() значительно превосходит другие при использовании append() и iterrows() остается последним для каждого сравнения.
Обратите внимание, что результаты этих тестов сильно зависят от других факторов, таких как ОС, среда, вычислительные ресурсы и т.д. Размер ваших данных также будет влиять на ваши результаты.
Вывод
Мы научились перебирать в DataFrame с тремя различными методами Pandas — items() , iterrows() , itertuples() . В зависимости от ваших данных и предпочтений вы можете использовать один из них в своих проектах.
Источник
Как вывести выборку строк в pandas
Подскажите, пожалуйста, как вывести выборку строк, где в столбце (например «Адрес покупателя») были бы значения «1521. «?
Предполагаю это будет через :
Когда так ввожу — не получается.
И сопутствующий вопрос: как обозвать эту получившуюся выборку, чтобы дальше с ней работать.
Ссылка на файлы .pynb и .xlsx:
1 ответ 1
Ошибка в том, что Series.isin(list-like-object) — ищет полные совпадения — поэтому в вашем случае ничего найдено не было. Для поиска подстрок можно динамически собрать регулярное выражение (пример ниже) и воспользоваться Series.str.contains(regex_pattern) .
Пример для Python 3.x (для Python 2.x возможно придется указывать u» перед именами столбцов):
Список почтовых индексов:
RegEx (регулярное выражение) для поиска указанных в списке индексов в строке:
Ищем в столбце Адрес покупателя подстроку по созданному выше RegEx и показываем только те строки, кот. удовлетворяют данному условию:
Пример поиска по начальным цыфрам индекса:
PS Лучше использовать явную адресацию:
или для Python 2.x в том случае если названия столбцов в UTF-8 :
Адресация столбцов в Pandas через точку не работает в следующих случаях:
- имя столбца содержит NON-ASCII символ(ы)
- имя столбца содержит пробелы/табуляции
- имя столбца совпадает с названием метода Pandas или Numpy
Источник
Моя шпаргалка по pandas
Один преподаватель как-то сказал мне, что если поискать аналог программиста в мире книг, то окажется, что программисты похожи не на учебники, а на оглавления учебников: они не помнят всего, но знают, как быстро найти то, что им нужно.
Возможность быстро находить описания функций позволяет программистам продуктивно работать, не теряя состояния потока. Поэтому я и создал представленную здесь шпаргалку по pandas и включил в неё то, чем пользуюсь каждый день, создавая веб-приложения и модели машинного обучения.

Нельзя сказать, что это — исчерпывающий список возможностей pandas , но сюда входят функции, которыми я пользуюсь чаще всего, примеры и мои пояснения по поводу ситуаций, в которых эти функции особенно полезны.
1. Подготовка к работе
Если вы хотите самостоятельно опробовать то, о чём тут пойдёт речь, загрузите набор данных Anime Recommendations Database с Kaggle. Распакуйте его и поместите в ту же папку, где находится ваш Jupyter Notebook (далее — блокнот).
Теперь выполните следующие команды.
После этого у вас должна появиться возможность воспроизвести то, что я покажу в следующих разделах этого материала.
2. Импорт данных
▍Загрузка CSV-данных
Здесь я хочу рассказать о преобразовании CSV-данных непосредственно в датафреймы (в объекты Dataframe). Иногда при загрузке данных формата CSV нужно указывать их кодировку (например, это может выглядеть как encoding=’ISO-8859–1′ ). Это — первое, что стоит попробовать сделать в том случае, если оказывается, что после загрузки данных датафрейм содержит нечитаемые символы.

Существует похожая функция для загрузки данных из Excel-файлов — pd.read_excel .
▍Создание датафрейма из данных, введённых вручную
Это может пригодиться тогда, когда нужно вручную ввести в программу простые данные. Например — если нужно оценить изменения, претерпеваемые данными, проходящими через конвейер обработки данных.
Данные, введённые вручную
▍Копирование датафрейма
Копирование датафреймов может пригодиться в ситуациях, когда требуется внести в данные изменения, но при этом надо и сохранить оригинал. Если датафреймы нужно копировать, то рекомендуется делать это сразу после их загрузки.
3. Экспорт данных
▍Экспорт в формат CSV
При экспорте данных они сохраняются в той же папке, где находится блокнот. Ниже показан пример сохранения первых 10 строк датафрейма, но то, что именно сохранять, зависит от конкретной задачи.
Экспортировать данные в виде Excel-файлов можно с помощью функции df.to_excel .
4. Просмотр и исследование данных
▍Получение n записей из начала или конца датафрейма
Сначала поговорим о выводе первых n элементов датафрейма. Я часто вывожу некоторое количество элементов из начала датафрейма где-нибудь в блокноте. Это позволяет мне удобно обращаться к этим данным в том случае, если я забуду о том, что именно находится в датафрейме. Похожую роль играет и вывод нескольких последних элементов.
Данные из начала датафрейма
Данные из конца датафрейма
▍Подсчёт количества строк в датафрейме
Функция len(), которую я тут покажу, не входит в состав pandas . Но она хорошо подходит для подсчёта количества строк датафреймов. Результаты её работы можно сохранить в переменной и воспользоваться ими там, где они нужны.
▍Подсчёт количества уникальных значений в столбце
Для подсчёта количества уникальных значений в столбце можно воспользоваться такой конструкцией:
▍Получение сведений о датафрейме
В сведения о датафрейме входит общая информация о нём вроде заголовка, количества значений, типов данных столбцов.
Сведения о датафрейме
Есть ещё одна функция, похожая на df.info — df.dtypes . Она лишь выводит сведения о типах данных столбцов.
▍Вывод статистических сведений о датафрейме
Знание статистических сведений о датафрейме весьма полезно в ситуациях, когда он содержит множество числовых значений. Например, знание среднего, минимального и максимального значений столбца rating даёт нам некоторое понимание того, как, в целом, выглядит датафрейм. Вот соответствующая команда:
Статистические сведения о датафрейме
▍Подсчёт количества значений
Для того чтобы подсчитать количество значений в конкретном столбце, можно воспользоваться следующей конструкцией:
Подсчёт количества элементов в столбце
5. Извлечение информации из датафреймов
▍Создание списка или объекта Series на основе значений столбца
Это может пригодиться в тех случаях, когда требуется извлекать значения столбцов в переменные x и y для обучения модели. Здесь применимы следующие команды:
Результаты работы команды anime[‘genre’].tolist()
Результаты работы команды anime[‘genre’]
▍Получение списка значений из индекса
Поговорим о получении списков значений из индекса. Обратите внимание на то, что я здесь использовал датафрейм anime_modified , так как его индексные значения выглядят интереснее.
Результаты выполнения команды
▍Получение списка значений столбцов
Вот команда, которая позволяет получить список значений столбцов:
Результаты выполнения команды
6. Добавление данных в датафрейм и удаление их из него
▍Присоединение к датафрейму нового столбца с заданным значением
Иногда мне приходится добавлять в датафреймы новые столбцы. Например — в случаях, когда у меня есть тестовый и обучающий наборы в двух разных датафреймах, и мне, прежде чем их скомбинировать, нужно пометить их так, чтобы потом их можно было бы различить. Для этого используется такая конструкция:
▍Создание нового датафрейма из подмножества столбцов
Это может пригодиться в том случае, если требуется сохранить в новом датафрейме несколько столбцов огромного датафрейма, но при этом не хочется выписывать имена столбцов, которые нужно удалить.
Результат выполнения команды
▍Удаление заданных столбцов
Этот приём может оказаться полезным в том случае, если из датафрейма нужно удалить лишь несколько столбцов. Если удалять нужно много столбцов, то эта задача может оказаться довольно-таки утомительной, поэтому тут я предпочитаю пользоваться возможностью, описанной в предыдущем разделе.
Результаты выполнения команды
▍Добавление в датафрейм строки с суммой значений из других строк
Для демонстрации этого примера самостоятельно создадим небольшой датафрейм, с которым удобно работать. Самое интересное здесь — это конструкция df.sum(axis=0) , которая позволяет получать суммы значений из различных строк.
Результат выполнения команды
Команда вида df.sum(axis=1) позволяет суммировать значения в столбцах.
Похожий механизм применим и для расчёта средних значений. Например — df.mean(axis=0) .
7. Комбинирование датафреймов
▍Конкатенация двух датафреймов
Эта методика применима в ситуациях, когда имеются два датафрейма с одинаковыми столбцами, которые нужно скомбинировать.
В данном примере мы сначала разделяем датафрейм на две части, а потом снова объединяем эти части:
Датафрейм, объединяющий df1 и df2
▍Слияние датафреймов
Функция df.merge , которую мы тут рассмотрим, похожа на левое соединение SQL. Она применяется тогда, когда два датафрейма нужно объединить по некоему столбцу.
Результаты выполнения команды
8. Фильтрация
▍Получение строк с нужными индексными значениями
Индексными значениями датафрейма anime_modified являются названия аниме. Обратите внимание на то, как мы используем эти названия для выбора конкретных столбцов.
Результаты выполнения команды
▍Получение строк по числовым индексам
Эта методика отличается от той, которая описана в предыдущем разделе. При использовании функции df.iloc первой строке назначается индекс 0 , второй — индекс 1 , и так далее. Такие индексы назначаются строкам даже в том случае, если датафрейм был модифицирован и в его индексном столбце используются строковые значения.
Следующая конструкция позволяет выбрать три первых строки датафрейма:
Результаты выполнения команды
▍Получение строк по заданным значениям столбцов
Для получения строк датафрейма в ситуации, когда имеется список значений столбцов, можно воспользоваться следующей командой:
Результаты выполнения команды
Если нас интересует единственное значение — можно воспользоваться такой конструкцией:
▍Получение среза датафрейма
Эта техника напоминает получение среза списка. А именно, речь идёт о получении фрагмента датафрейма, содержащего строки, соответствующие заданной конфигурации индексов.
Результаты выполнения команды
▍Фильтрация по значению
Из датафреймов можно выбирать строки, соответствующие заданному условию. Обратите внимание на то, что при использовании этого метода сохраняются существующие индексные значения.
Результаты выполнения команды
9. Сортировка
Для сортировки датафреймов по значениям столбцов можно воспользоваться функцией df.sort_values :
Результаты выполнения команды
10. Агрегирование
▍Функция df.groupby и подсчёт количества записей
Вот как подсчитать количество записей с различными значениями в столбцах:
Результаты выполнения команды
▍Функция df.groupby и агрегирование столбцов различными способами
Обратите внимание на то, что здесь используется reset_index() . В противном случае столбец type становится индексным столбцом. В большинстве случаев я рекомендую делать то же самое.
▍Создание сводной таблицы
Для того чтобы извлечь из датафрейма некие данные, нет ничего лучше, чем сводная таблица. Обратите внимание на то, что здесь я серьёзно отфильтровал датафрейм, что ускорило создание сводной таблицы.
Результаты выполнения команды
11. Очистка данных
▍Запись в ячейки, содержащие значение NaN, какого-то другого значения
Здесь мы поговорим о записи значения 0 в ячейки, содержащие значение NaN . В этом примере мы создаём такую же сводную таблицу, как и ранее, но без использования fill_value=0 . А затем используем функцию fillna(0) для замены значений NaN на 0 .
Таблица, содержащая значения NaN
Результаты замены значений NaN на 0
12. Другие полезные возможности
▍Отбор случайных образцов из набора данных
Я использую функцию df.sample каждый раз, когда мне нужно получить небольшой случайный набор строк из большого датафрейма. Если используется параметр frac=1 , то функция позволяет получить аналог исходного датафрейма, строки которого будут перемешаны.
Результаты выполнения команды
▍Перебор строк датафрейма
Следующая конструкция позволяет перебирать строки датафрейма:
Результаты выполнения команды
▍Борьба с ошибкой IOPub data rate exceeded
Если вы сталкиваетесь с ошибкой IOPub data rate exceeded — попробуйте, при запуске Jupyter Notebook, воспользоваться следующей командой:
Итоги
Здесь я рассказал о некоторых полезных приёмах использования pandas в среде Jupyter Notebook. Надеюсь, моя шпаргалка вам пригодится.
Уважаемые читатели! Есть ли какие-нибудь возможности pandas , без которых вы не представляете своей повседневной работы?
Источник







