- BestProg
- Функции обрабатывающие регистр символов в строке
- Содержание
- Метод string lower() и upper() в Python
- Параметры
- Возвращаемое значение
- Пример 1: Преобразование строки в нижний регистр
- Пример метода lower()
- Параметры
- Возвращаемое значение
- Пример 1: Преобразование строки в верхний регистр
- Пример 2: Как в программе используется?
- 7 Способов сделать символы прописными С помощью Python
- 7 Способов сделать символы прописными С помощью Python
- Синтаксис создания символов в верхнем регистре С помощью Python
- Примеры преобразования строки в верхнем регистре python
- 1. Первая буква в заглавной строке в Python
- 2. Первая буква каждого слова Capital в Python
- 3. Чтобы соответствовать, если две строки одинаковы
- 4. Чтобы проверить, находится ли строка уже в верхнем регистре или нет
- 5. Сделать каждый альтернативный символ прописными буквами
- 6. Преобразование строки в верхний регистр Python без встроенной функции
- 7. Преобразование строки из верхнего регистра Python в нижний
- Надо Читать:
- Вывод
- Строковые методы
- Введение
- Примеры
- Изменение заглавной буквы строки
- Разбить строку на основе разделителя на список строк
- Заменить все вхождения одной подстроки другой подстрокой
- str.format и f-strings: форматировать значения в строку
- Подсчет количества появлений подстроки в строке
- Проверьте начальный и конечный символы строки
- Проверка того, из чего состоит строка
- str.translate: перевод символов в строке
- Удаление нежелательных начальных / конечных символов из строки
- Сравнение строк без учета регистра
- Объединить список строк в одну строку
- Полезные константы строкового модуля
- Сторнирование строки
- Обоснуйте строки
- Преобразование между str или байтовыми данными и символами юникода
- Строка содержит
- Синтаксис
- Параметры
- Примечания
BestProg
Функции обрабатывающие регистр символов в строке
Содержание
Поиск на других ресурсах:
1. Функция str.capitalize() . Первый символ строки становится прописным
Функция capitalize() возвращает копию строки с первым символом в верхнем регистре, а другие символы в нижнем регистре.
Пример.
2. Функция str.casefold() . Вернуть свернутую копию строки
Функция str.casefold() возвращает свернутую копию строки. Понятие «свернутая копия» строки означает, что в такой копии удалены все отличия регистра символов в строке.
Особенность «свернутой» копии строки состоит в том, что функция lower() не может быть применена к некоторым символам, а функция casefold() может. Примером такого символа есть немецкий символ ‘ß’, который в функции casefold() заменяется на символы ss в отличие от функции lower() .
Функция введена в Python начиная из версии 3.3.
Пример.
3. Функция str.lower() . Преобразование регистра символов
Функция str.lower() преобразовывает символы в нижний регистр.
Пример.
4. Функция str.swapcase() . Вернуть копию строки с преобразованием строчных символов в заглавные и наоборот
Функция str.swapcase() возвращает копию строки с заглавными буквами, преобразованными в строчные и, наоборот, строчными преобразованными в заглавные. Общая форма вызова функции следующая:
- s1 – исходная строка, которую нужно преобразовать;
- s2 – результирующая строка в которой все заглавные символы преобразованы в строчные, а все строчные преобразованы в заглавные.
Для данной функции нельзя утверждать, что нижеследующее выражение
будет всегда выполняться.
Пример.
5. Функция str.title() . Вернуть строку с заглавными буквами в словах
Функция str.title() возвращает строку, в которой все слова начинаются с заглавной буквы. Другие символы в этих словах есть строчные. Общая форма использования функции следующая:
- s1 – исходная строка;
- s2 – результирующая строка, в которой реализуется корректировка символов, которые есть началами слов.
Функция имеет одну особенность. Символ ‘\» апострофа образовывает границу слова. В некоторых случаях это нежелательно. Во избежание этого недостатка нужно использовать регулярные выражения.
Пример.
6. Функция str.upper() . Конвертировать символы строки в верхний регистр
Функция str.upper() позволяет получить копию строки в которой все символы находятся в верхнем регистре. Согласно документации Python общая форма функции следующая:
- s1 – исходная строка;
- s2 – результирующая строка-копия, в которой символы нижнего регистра строки s1 заменены на символы верхнего регистра.
Конвертирование символов осуществляется только для символов имеющих верхний регистр. Это символы, которые включены в следующие категории:
- «Lu» – Letter uppercase;
- «Ll» – Letter lowercase;
- «Lt» – Letter titlecase.
Источник
Метод string lower() и upper() в Python
Метод string lower() преобразует все символы верхнего регистра в строке в символы нижнего регистра и возвращает их.
Параметры
Метод в Python не принимает никаких параметров.
Возвращаемое значение
Команда возвращает строку в нижнем регистре из данной строки. Он преобразует все символы верхнего регистра в нижний регистр.
Если символы верхнего регистра отсутствуют, возвращается исходная строка.
Пример 1: Преобразование строки в нижний регистр
Пример метода lower()
Примечание: Если вы хотите преобразовать строку в верхний регистр, используйте upper(). Вы также можете использовать метод swapcase() для переключения между нижним регистром и верхним регистром.
Метод string upper() преобразует все символы нижнего регистра в строке в символы верхнего регистра и возвращает их.
Параметры
Метод upper() в Python не принимает никаких параметров.
Возвращаемое значение
Метод возвращает строку в верхнем регистре из данной строки. Он преобразует все символы нижнего регистра в верхний регистр.
Если строчные символы отсутствуют, возвращается исходная строка.
Пример 1: Преобразование строки в верхний регистр
Пример 2: Как в программе используется?
Примечание: Если вы хотите преобразовать строку в нижний регистр, используйте lower(). Вы также можете использовать swapcase() для переключения между нижним регистром и верхним регистром.
Источник
7 Способов сделать символы прописными С помощью Python
Для преобразования строк в python в верхний регистр или наоборот существует функция upper(). А для проверки того, находится ли строка в верхнем регистре, используется isupper ().
Автор: Team Python Pool
Дата записи
7 Способов сделать символы прописными С помощью Python
Причина, по которой python стал таким популярным языком программирования, заключается в том, что он предоставляет программистам множество универсальных и стандартных библиотек, которые легко доступны, поэтому нам даже не нужно загружать их явно. Одной из таких библиотек в python является upper(), которая преобразует строки в python в верхний регистр.
Это означает, что если у нас есть строка из нижних букв (например – “HELLO, how are you”), мы можем использовать upper() для преобразования ее в заглавные буквы (“HELLO, HOW ARE YOU”). Мы не только будем знать, как перевести все буквы в верхний регистр, но и будем знать, как преобразовать только Первую букву и каждую альтернативную букву в верхний регистр.
Синтаксис создания символов в верхнем регистре С помощью Python
Поскольку upper ()-это встроенный метод, нам даже не нужно его импортировать. Мы можем использовать его прямо так –
Примечание – Он не принимает никаких аргументов.
Примеры преобразования строки в верхнем регистре python
- Первая буква в сильной столице
- Первая буква каждого слова Заглавная
- Чтобы соответствовать, если две строки одинаковы
- Проверьте, есть ли строка уже в верхнем регистре или нет
- Чтобы сделать каждый альтернативный символ прописными буквами
- Преобразование строки в верхний регистр Python без встроенной функции
- Преобразование строки из верхнего регистра Python в нижний регистр
1. Первая буква в заглавной строке в Python
Для этого у нас есть встроенная функция с именем capitalize()
Иногда мы забываем, как называется функция, поэтому мы также должны знать, как сделать то же самое, не используя эти функции.
2. Первая буква каждого слова Capital в Python
Предположим, мы хотим, чтобы все слова в строке были прописными. Для этого у нас есть метод, доступный в python, называемый title().
Мы можем сделать это без использования встроенной функции-title (), как это-
3. Чтобы соответствовать, если две строки одинаковы
Если мы хотим сравнить две строки с точки зрения того, являются ли они одинаковыми или нет (не принимая во внимание верхний и нижний регистр).
4. Чтобы проверить, находится ли строка уже в верхнем регистре или нет
Есть много случаев, когда мы принимаем входные данные от пользователя, и это не обязательно, чтобы каждый пользователь вводил данные в одном и том же формате. Но нам нужно хранить данные в том же формате, поэтому, если строка уже находится в верхнем регистре, выведите “уже в верхнем регистре”, иначе преобразуйте ее в верхний регистр.
5. Сделать каждый альтернативный символ прописными буквами
6. Преобразование строки в верхний регистр Python без встроенной функции
Мы можем преобразовать любую строку в верхний регистр без использования какой-либо встроенной функции. Каждый символ имеет href=”https://en.wikipedia.org/wiki/ASCII”>ASCII значение. Например. Мы можем воспользоваться этим фактом и преобразовать строчные символы в прописные. href=”https://en.wikipedia.org/wiki/ASCII”>ASCII значение. Например. Мы можем воспользоваться этим фактом и преобразовать строчные символы в прописные.
Обратите внимание, что значение ASCII для ‘A’ – ‘Z’ колеблется от 65-90, а для ‘a’ – ‘z’ – от 97-122.
7. Преобразование строки из верхнего регистра Python в нижний
Python также предоставляет некоторые аналоги своих методов upper() и isupper (). В Python прописные символы могут быть преобразованы в строчные с помощью lower().
Аналогично, если мы хотим проверить, находится ли строка уже в нижнем регистре или нет, мы используем islower().
Все остальные функции работают так же для lower (), как мы уже обсуждали в upper().
Надо Читать:
- Как преобразовать строку в нижний регистр в
- Как вычислить Квадратный корень
- Пользовательский ввод | Функция ввода () | Ввод с клавиатуры
- Лучшая книга для изучения Python
Вывод
Встроенные функции Python предоставляют способ преобразования строки в python из верхнего регистра в нижний и наоборот. Обычно, когда мы хотим сохранить все текстовые данные в одном и том же формате (верхний или нижний регистр), мы используем эти методы.
Попробуйте запустить программы на вашей стороне и дайте мне знать, если у вас есть какие-либо вопросы.
Источник
Строковые методы

Введение
Примеры
Изменение заглавной буквы строки
Тип строки Python предоставляет множество функций, которые влияют на использование заглавных букв в строке. Они включают :
- str.casefold
- str.upper
- str.lower
- str.capitalize
- str.title
- str.swapcase
С юникод строк (по умолчанию в Python 3), эти операции не являются 1: 1 отображения или обратимым. Большинство из этих операций предназначены для отображения, а не нормализации. str.casefold()
str.casefold создает строчную строку, которая подходит для случая нечувствительных сравнений. Это более агрессивный , чем str.lower и может изменить строки, которые уже находятся в нижнем регистре или вызывают строки , чтобы расти в длину, и не предназначена для отображения.
Преобразования, которые происходят в рамках casefolding, определяются Консорциумом Unicode в файле CaseFolding.txt на их веб-сайте. str.upper()
str.upper принимает каждый символ в строке и преобразует его в верхнем регистре эквивалента, например:
str.lower делает обратное; он берет каждый символ в строке и преобразует его в строчный эквивалент:
str.capitalize возвращает заглавную версию строки, то есть, он делает первый символ имеет верхний регистр , а остальные нижние:
str.title возвращает название обсаженной версии строки, то есть, каждая буква в начале слова производится в верхнем регистре , а все остальные сделаны в нижнем регистре:
str.swapcase возвращает новый объект строки , в которой все строчные символы поменяны местами в верхний регистр и все символы верхнего регистра в нижний:
Использование в качестве str методов класса
Следует отметить , что эти методы могут быть названы либо на струнных объектов (как показано выше) или как метод класса от str класса (с явным вызовом str.upper и т.д.)
Это особенно полезно при применении одного из этих методов для многих строк сразу, скажем, на map функции.
Разбить строку на основе разделителя на список строк
str.split принимает строку и возвращает список подстрок исходной строки. Поведение отличается в зависимости от того sep предусмотрен или опущен аргумент.
Если sep не предусмотрен, или нет None , то происходит расщепление везде , где есть пробела. Однако начальные и конечные пробелы игнорируются, и несколько последовательных пробельных символов обрабатываются так же, как один пробельный символ:
sep параметр может быть использован для определения строки разделителей. Исходная строка разделяется там, где встречается строка-разделитель, а сам разделитель отбрасывается. Несколько последовательных разделители не обрабатываются так же , как однократный, а вызвать пустые строки , которые будут созданы.
По умолчанию заключается в разделении на каждом появлении разделителя, однако maxsplit параметр ограничивает количество расщеплений , которые происходят. Значение по умолчанию -1 означает , что нет предела:
str.rsplit ( «правый раскол») отличается от str.split ( «левый сплит») , когда maxsplit указано. Расщепление начинается в конце строки, а не в начале:
Примечание: Python определяет максимальное число разделений , выполняемых, в то время как большинство других языков программирования указать максимальное количество подстрок созданных. Это может создать путаницу при переносе или сравнении кода.
Заменить все вхождения одной подстроки другой подстрокой
Пайтона str типа также есть метод для замены вхождений одной подстроки с другой подстроки в заданной строке. Для более сложных случаев можно использовать re.sub . str.replace(old, new[, count]) :
str.replace принимает два аргумента , old и new , содержащий old подстроку , которая должна быть заменена на new подстроку. Необязательный аргумент count определяет число замен , чтобы быть:
Например, для того , чтобы заменить ‘foo’ с ‘spam’ в следующей строке, мы можем назвать str.replace с old = ‘foo’ и new = ‘spam’ :
Если данная строка содержит несколько примеров , которые соответствуют old аргументу, все вхождения заменяются значением подаваемого в new :
если, конечно, мы не поставляем значение для count . В этом случае count вхождения собираются заменяются:
str.format и f-strings: форматировать значения в строку
Python обеспечивает интерполяцию строки и функциональность форматирования через str.format функции, введенной в версии 2.6 и F-строк , введенных в версии 3.6.
Даны следующие переменные:
Следующие утверждения все эквивалентны
Для справки, Python также поддерживает классификаторы в стиле C для форматирования строк. Примеры , приведенные ниже, эквивалентны тем , которые выше, но str.format вариантов являются предпочтительными из — за преимущества в гибкости, последовательности обозначений и расширяемости:
Скобки используются для интерполяции в str.format также может быть пронумерована для уменьшения дублирования при форматировании строк. Например, следующее эквивалентно:
В то время как официальная документация питона, как обычно, достаточно тщательно, pyformat.info имеет большой набор примеров с подробными объяснениями.
Кроме того, < и >символы могут быть экранированы с помощью двойных скобок:
См Строка форматирования для получения дополнительной информации. str.format() был предложен в PEP 3101 и F-строк в PEP 498 .
Подсчет количества появлений подстроки в строке
Один метод доступен для подсчета количества вхождений подстроки в другой строки, str.count . str.count(sub[, start[, end]])
str.count возвращает int , указывающее количество неперекрывающихся вхождений подстрок sub в другой строке. Необязательные аргументы start и end указывают на начало и конец , в котором поиск будет происходить. По умолчанию start = 0 и end = len(str) означает всю строку будет искать:
Задавая различные значения для start , end , мы можем получить более локализованный поиск и сосчитать, например, если start равно 13 призыва к:
Проверьте начальный и конечный символы строки
Для того , чтобы проверить начало и окончание данной строки в Python, можно использовать методы str.startswith() и str.endswith() . str.startswith(prefix[, start[, end]])
Как следует это имя, str.startswith используется для проверки , начинается ли заданная строка с заданными символами в prefix .
Необязательные аргументы start и end указать начальную и конечную точки , из которых тестирование будет начать и закончить. В следующем примере, указав начальное значение 2 наша строка будет просматриваться с позиции 2 , а затем:
Это дает True , так как s[2] == ‘i’ и s[3] == ‘s’ .
Вы можете также использовать tuple , чтобы проверить , если он начинается с какой — либо из набора строк
str.endswith(prefix[, start[, end]])
str.endswith точно похож на str.startswith с той лишь разницей, что он ищет окончание символов и не начиная символов. Например, чтобы проверить, заканчивается ли строка полной остановкой, можно написать:
как и с startswith более одного символа может использоваться как окончание последовательности:
Вы можете также использовать tuple , чтобы проверить , если он заканчивается любой из набора строк
Проверка того, из чего состоит строка
Пайтона str тип также имеет целый ряд методов , которые могут быть использованы для оценки содержимого строки. Это str.isalpha , str.isdigit , str.isalnum , str.isspace . Капитализация может быть проверена с str.isupper , str.islower и str.istitle . str.isalpha
str.isalpha не принимает никаких аргументов и возвращает True , если все символы в данной строке являются буквенными, например:
В краевой случае пустая строка вычисляет значение False при использовании «».isalpha() . str.isupper , str.islower , str.istitle
Эти методы проверяют использование заглавных букв в заданной строке.
str.isupper это метод , который возвращает True , если все символы в данной строке в верхнем регистре и False иначе.
С другой стороны , str.islower это метод , который возвращает True , если все символы в данной строке в нижнем регистре и False иначе.
str.istitle возвращает True , если данная строка названия обсаженное; то есть каждое слово начинается с заглавной буквы, за которой следуют строчные буквы.
str.isdecimal , str.isdigit , str.isnumeric
str.isdecimal возвращает строка , является ли последовательность десятичных цифр, пригодная для представления десятичного числа.
str.isdigit включает в себя цифру не в форме , подходящей для представления десятичного числа, такие , как надстрочные цифры.
str.isnumeric включает в себя любые числовые значения, даже если не цифры, такие как значения вне диапазона 0-9.
Байтовые строки ( bytes в Python 3, str в Python 2), поддерживает только isdigit , который проверяет только основные ASCII цифр.
Как str.isalpha пустая строка вычисляет значение False . str.isalnum
Это сочетание str.isalpha и str.isnumeric , в частности , он имеет значение True , если все символы в данной строке являются буквенно — цифровыми, то есть они состоят из буквенных или цифровых символов:
Возвращает True , если строка содержит только пробельные символы.
Иногда строка выглядит «пустой», но мы не знаем, так ли это, потому что она содержит только пробелы или вообще не содержит символов
Чтобы покрыть этот случай нам нужен дополнительный тест
Но самый короткий путь , чтобы проверить , если строка пуста или содержит только пробельные символы, чтобы использовать strip (без аргументов она удаляет все начальные и конечные пробельные символы)
str.translate: перевод символов в строке
Python поддерживает translate метод на str типа , который позволяет указать таблицу преобразования (используется для замены), а также любые символы , которые должны быть удалены в процессе.
параметр Описание table Это таблица поиска, которая определяет отображение от одного символа к другому. deletechars Список символов, которые должны быть удалены из строки.
maketrans метод ( str.maketrans в Python 3 и string.maketrans в Python 2) позволяет создать таблицу перевода.
translate метод возвращает строку , которая является переведенной копией исходной строки.
Вы можете установить table аргумент None , если требуется только для удаления символов.
Удаление нежелательных начальных / конечных символов из строки
Три метода при условии , что предлагают возможность раздеться начальные и конечные символы из строки: str.strip , str.rstrip и str.lstrip . Все три метода имеют одинаковую подпись, и все три возвращают новый строковый объект с удаленными нежелательными символами. str.strip([chars])
str.strip действует на заданной строки и удаляет (полоски) или каких — либо ведущих задних символов , содержащихся в аргументе chars ; если chars не входит в комплект или нет None , все пробельные символы удаляются по умолчанию. Например:
Если chars поставляются, все символы , содержащиеся в нем, удаляются из строки, которая возвращается. Например:
str.rstrip([chars]) и str.lstrip([chars])
Эти методы имеют ту же семантику и аргументы с str.strip() , их отличие заключается в том направлении , откуда они начинаются. str.rstrip() начинается с конца строки в то время как str.lstrip() расщепляется с начала строки.
Например, при использовании str.rstrip :
В то время как, используя str.lstrip :
Сравнение строк без учета регистра
Сравнение строки без учета регистра кажется чем-то тривиальным, но это не так. В этом разделе рассматриваются только строки Unicode (по умолчанию в Python 3). Обратите внимание, что Python 2 может иметь незначительные недостатки по сравнению с Python 3 — более поздняя обработка юникода гораздо более полная.
Первое, на что следует обратить внимание, это то, что преобразования с удалением регистра в юникоде не являются тривиальными. Существует текст , для которого text.lower() != text.upper().lower() , Например, «ß» :
Но предположим, что вы хотели регистронезависмо сравнивать «BUSSE» и «Buße» . Черт возьми, вы , вероятно , также хотят , чтобы сравнить «BUSSE» и «BUẞE» равный — это новая форма капитала. Рекомендуемый способ заключается в использовании casefold :
Не просто использовать lower . Если casefold не доступен, делая .upper().lower() помогает (но только немного).
Тогда вы должны рассмотреть акценты. Если визуализатор шрифт хорошо, вы , вероятно , думаете , «ê» == «ê» — но это не так :
Это потому что они на самом деле
Самый простой способ справиться с этим unicodedata.normalize . Вы , вероятно , хотите использовать NFKD нормализации, но не стесняйтесь проверить документацию. Тогда один
Чтобы закончить, здесь это выражается в функциях:
Объединить список строк в одну строку
Строка может быть использована в качестве разделителя , чтобы присоединиться к списку строк вместе в одну строку с помощью join() метод. Например, вы можете создать строку, где каждый элемент в списке разделен пробелом.
В следующем примере строковые элементы разделяются тремя дефисами.
Полезные константы строкового модуля
Пайтона string модуль предоставляет константы для операций , связанных строк. Для того, чтобы использовать их, импортировать string модуля:
Стечение ascii_lowercase и ascii_uppercase :
Содержит все символы нижнего регистра ASCII:
Содержит все символы ASCII в верхнем регистре:
Содержит все десятичные цифры:
Содержит все шестнадцатеричные символы:
Содержит все восьмеричные символы:
Содержит все символы , которые считаются знаки препинания в C локали:
Содержит все символы ASCII, которые считаются пробелами:
В режиме сценария, print(string.whitespace) напечатает фактические символы, используйте str , чтобы получить вернулся выше строка. string.printable :
Содержит все символы, которые считаются печатными; сочетание string.digits , string.ascii_letters , string.punctuation и string.whitespace .
Сторнирование строки
Строка может реверсировать с использованием встроенных в reversed() функции, которая принимает строку и возвращает итератор в обратном порядке.
reversed() могут быть обернуты в вызове ».join() , чтобы сделать строку из итератора.
В то время как с использованием reversed() может быть более удобными для чтения для непосвященных пользователей Python, используя расширенную нарезку с шагом -1 быстрее и более кратким. Вот, попробуйте реализовать это как функцию:
Обоснуйте строки
Python предоставляет функции для выравнивания строк, позволяя заполнять текст, чтобы упростить выравнивание различных строк.
Ниже приведен пример str.ljust и str.rjust :
40 -> 2555 миль (4112 км.) 19 -> 63 миль. (102 км.) 5 -> 1381 миль. (2222 км.) 93 -> 189 миль. (305 км.)
ljust и rjust очень похожи. Оба имеют width параметр и необязательный fillchar параметр. Любая строка , создаваемая эти функции, по крайней мере до тех пор , как width параметр , который был передан в функцию. Если строка длиннее , чем width alread, она не усекается. fillchar аргумент, который по умолчанию используется символ пробела ‘ ‘ должен быть один символ, а не multicharacter строка.
ljust функция подушечки конца строки она называется на с fillchar до тех пор, пока width длиной символов. rjust функция подушечки начала строки в подобной манере. Таким образом, l и r в названиях этих функций относятся к стороне , что исходная строка, а не fillchar , расположена в выходной строке.
Преобразование между str или байтовыми данными и символами юникода
Содержимое файлов и сетевых сообщений может представлять собой закодированные символы. Их часто нужно преобразовывать в юникод для правильного отображения.
В Python 2 вам может потребоваться преобразовать данные str в символы Unicode. По умолчанию ( » , «» и т.д.) является строкой ASCII, с любыми значениями за пределами диапазона ASCII отображается в виде уцелевших значений. Unicode строки u» (или u»» и т.д.).
В Python 3 вам может потребоваться преобразовать массивы байтов (называемые «байтовым литералом») в строки символов Unicode. По умолчанию теперь строка Unicode, и байтовой строки литералов теперь должны быть введены как b» , b»» , и т.д. Байт буквальным будет возвращать True в isinstance(some_val, byte) , предполагая some_val быть строка , которая может быть закодированы в байтах.
Строка содержит
Python делает его чрезвычайно интуитивным, чтобы проверить, содержит ли строка заданную подстроку. Просто используйте in операторе:
Примечание: тестирование пустой строки всегда будет приводить True :
Синтаксис
Параметры
Примечания
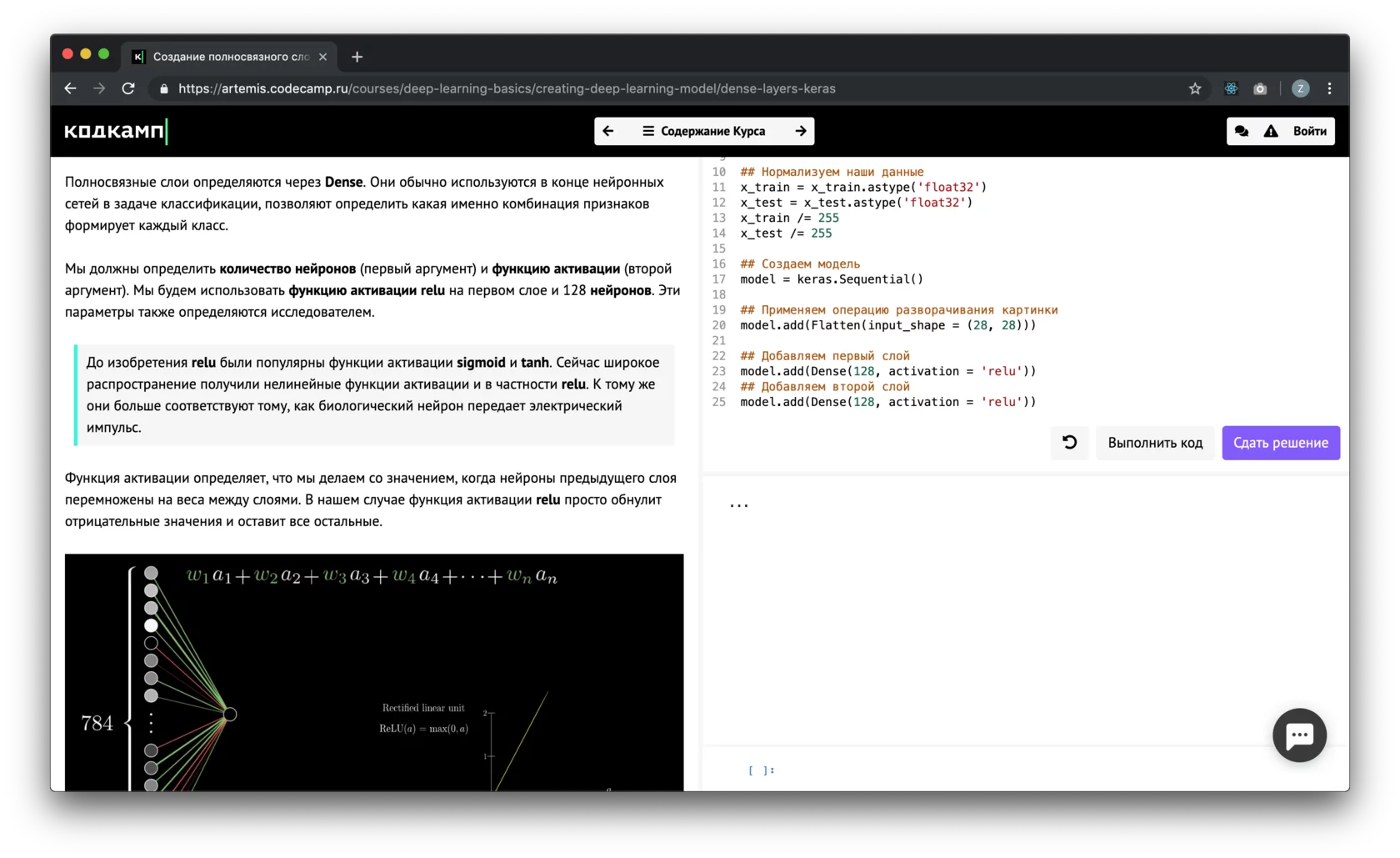
Научим основам Python и Data Science на практике
Это не обычный теоритический курс, а онлайн-тренажер, с практикой на примерах рабочих задач, в котором вы можете учиться в любое удобное время 24/7. Вы получите реальный опыт, разрабатывая качественный код и анализируя реальные данные.
Источник







