- Примеры разделения датасета на train и test c Scikit-learn
- Случайное перемешивание строк
- Стратификация (равномерное распределение) классов
- Дополнительное разделение
- Scikit-Learn Pipelines with Custom Transformer — A Step by Step Guide.
- Руководство по машинному обучению для начинающих: модель прогноза выживших на «Титанике»
- Авторизуйтесь
- Руководство по машинному обучению для начинающих: модель прогноза выживших на «Титанике»
- Начало работы
- Введение в машинное обучение
- Машинное обучение с Python
- Тестирование для предотвращения переобучения
- Практика
Примеры разделения датасета на train и test c Scikit-learn
Если вы разбиваете датасет на данные для обучения и тестирования, нужно помнить о некоторых моментах. Далее следует обсуждение трех передовых практик, которые стоит учитывать при подобном разделении. А также демонстрация того, как реализовать эти соображения в Python.
В данной статье обсуждаются три конкретных особенности, которые следует учитывать при разделении набора данных, подходы к решению связанных проблем и практическая реализация на Python.
Для наших примеров мы будем использовать модуль train_test_split библиотеки Scikit-learn, который очень полезен для разделения датасетов, независимо от того, будете ли вы применять Scikit-learn для выполнения других задач машинного обучения. Конечно, можно выполнить такие разбиения каким-либо другим способом (возможно, используя только Numpy). Библиотека Scikit-learn включает полезные функции, позволяющее сделать это немного проще.
Возможно, вы использовали этот модуль для разделения данных в прошлом, но при этом не приняли во внимание некоторые детали.
Случайное перемешивание строк
Первое, на что следует обратить внимание: перемешаны ли ваши экземпляры? Это следует делать пока нет причин не перетасовывать данные (например, они представляют собой временные интервалы). Мы должны убедиться в том, что наши экземпляры не разбиты на выборки по классам. Это потенциально вносит в нашу модель некоторую нежелательную предвзятость.
Например, посмотрите, как одна из версий набора данных iris, упорядочивает свои экземпляры при загрузке:
Если такой набор данных с тремя классами при равном числе экземпляров в каждом разделить на две выборки: 2/3 для обучения и 1/3 для тестирования, то полученные поднаборы будут иметь нулевое пересечение классовых меток. Это, очевидно, недопустимо при изучении признаков для предсказания классов. К счастью, функция train_test_split по умолчанию автоматически перемешивает данные (вы можете переопределить это, установив для параметра shuffle значение False ).
- В функцию должны быть переданы как вектор признаков, так и целевой вектор (X и y).
- Для воспроизводимости вы должны установить аргумент random_state .
- Также необходимо определить либо train_size , либо test_size , но оба они не нужны. Если вы явно устанавливаете оба параметра, они должны составлять в сумме 1.
Вы можете убедится, что теперь наши классы перемешаны.
Стратификация (равномерное распределение) классов
Данное размышление заключается в следующем. Равномерно ли распределено количество классов в наборах данных, разделенных для обучения и тестирования?
Это не равная разбивка. Главная идея заключается в том, получает ли наш алгоритм равные возможности для изучения признаков каждого из представленных классов и последующего тестирования результатов обучения, на равном числе экземпляров каждого класса. Хотя это особенно важно для небольших наборов данных, желательно постоянно уделять внимание данному вопросу.
Мы можем задать пропорцию классов при разделении на обучающий и проверяющий датасеты с помощью параметра stratify функции train_test_split . Стоит отметить, что мы будем стратифицировать в соответствии распределению по классам в y .
Сейчас это выглядит лучше, и представленные числа говорят нам, что это наиболее оптимально возможное разделение.
Дополнительное разделение
Третье соображение относится к проверочным данным (выборке валидации). Есть ли смысл для нашей задачи иметь только один тестовый датасет. Или мы должны подготовить два таких набора — один для проверки наших моделей во время их точной настройки, а еще один — в качестве окончательного датасета для сравнения моделей и выбора лучшей.
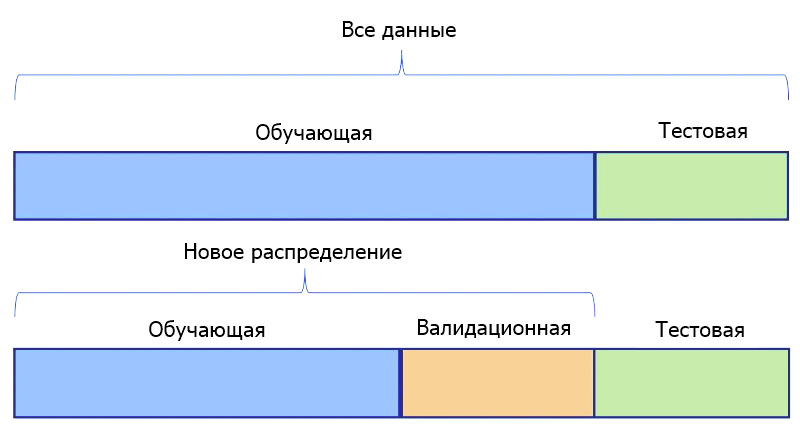
Если мы определим 2 таких набора, это будет означать, что одна выборка, будет храниться до тех пор, пока все предположения не будут проверены, все гиперпараметры не настроены, а все модели обучены для достижения максимальной производительности. Затем она будет показана моделям только один раз в качестве последнего шага в наших экспериментах.
Если вы хотите использовать датасеты для тестирования и валидации, создать их с помощью train_test_split легко. Для этого мы разделяем весь набор данных один раз для выделения обучающей выборки. Затем еще раз, чтобы разбить оставшиеся данные на датасеты для тестирования и валидации.
Ниже, используя набор данных digits, мы разделяем 70% для обучения и временно назначаем остаток для тестирования. Не забывайте применять методы, описанные выше.
Источник
Scikit-Learn Pipelines with Custom Transformer — A Step by Step Guide.


Data and Model Algorithm are the two core modules around which complete Machine Learning is contingent on. Within Data module, data extraction and data per-processing (or better known as feature engineering) play a crucial role in the complete model building life cycle.
In real life, any Machine Learning problem tends to have hundreds of input features around which solution needs to be conceptualized. To understand the data characteristics and generate fitment analysis report to respective use case, data need to be cleaned and processed via different techniques which are not limited to only Encoding Categorical values, Scaling Continuous features, Imputing , Normalization etc. This data transformation process becomes very tedious when dealing with large number of input features.
That’s why it is always a good practice to streamline this complete transformation process which can be applied on train and test data both seamlessly. That’s where Scikit-Learn Pipeline comes into picture to enablement this streamline transformation with a sequential list of Transformers and a final Estimator (Classifier). To avoid more theory into his post, if you want to read more about Transformers and Estimators, Sklearn tutorial site has good explanation on these terms.
In this post, I will try to cover following aspects.
- How to write Standard Transformers in sklearn pipeline
- How to write Custom Transformers and add them into sklearn pipeline
- Finally, How to use Sklearn Pipeline for model building and prediction
Note: I am using ‘Titanic-Survivor’ problem data set which is a Classification problem to explain Sklearn Pipeline integration.
To start with Sklearn Pipline Transformers, first I have imported the data into my Jupyter notebook. ‘ PassengerId’ column is dropped as it wont be used in model training.

In this data set, there are about 9 input features and 1 output label i.e. ‘Survived’.
- Pclass, Sex, SibSp, Parch and Embarked are Categorical features. We will apply Standard transformers to handle empty values and to encode them into Continuous values.
- Age and Fare are Continuous features. We will apply Standard transformers to handle empty values and to perform feature scaling
- Name and Cabin are Free-Text features and can not be directly used in model training so we will write custom transformation to transform them into some useful data
Split the data into train and test data and group Column names according to theirs data type.

To start with data transformation,
- Standard Transformers: Lets first write different standard transformer for each data type (categorical and continuous). Here I created numeric_transformer and categorical_transformer for processing continuous and categorical features values. In numeric_transformer, there are two steps; first is to replace empty (NaN) values with median of respective column. Second step is to apply scaling on continuous features. Similarly there are two steps in categorical_transformer for imputing and applying One Hot Encoding on categorical attributes. Here, all these Transformers such as SimpleImputer, StandardScalar, OneHotEnocder will have in-built implementation of ‘fit’ and ‘transform’ method which will be invoked on pipeline execution.

On execution of Pipeline’s fit method, Transformer’s ‘fit’ and ‘transform’ method will be called sequentially.
Where, on execution of Pipeline’s predict method, only Transformer’s transform method will be called.

Let me explain fit and transform methods usage in detail by taking example of ‘Cabin’ input feature. For code snippet, refer above screenshot.
In the ‘fit’ method
- For ‘Cabin’ feature, replacing all empty (na) values with ‘U’
- Replacing cabin values with first char of theirs respective values
- In next lines, we are determining unique values of ‘Cabin’ feature (via get_dummies method) and saving it in ‘self.cabin_columns’. It will be used in ‘transform’ method.
In the ‘transform’ method
- For ‘Cabin’ feature, replacing all empty (na) values with ‘U’
- Replacing cabin values with first char of theirs respective values
- In next lines, we are using get_dummies method to convert Cabin’s categorical values into numeric by creating new columns for each unique value.
- We are re-indexing these new columns based on already saved ‘self.cabin_columns’ values. The purpose of doing this is to avoid addition of new column based on new Cabin value in test data. Otherwise, model prediction will get fail on test data due to feature count mismatch. That’s why, we are not applying Label Encoder or One Hot Encoder on this feature and going with Custom Transformer. For more details, please refer this link.
Similarly, I have created one more Custom Transformer for ‘Name’ input feature.
ColumnTransformer to combine all transformers definition
Next step is to combine all transformers definition using ColumnTransformer as shown in below screenshot. When we execute this block, ‘ _init_’ method will be invoked of each Custom transformer.

Assembling — Combine Transformers and Estimators
This is the final step where we combine Transformers and Estimators (in this example, it is RandomForestClassifier) and create final pipeline that will be used to train a model and also in prediction.

Pipeline ‘fit’ method
- It is used for training a model on train data
- It accepts two parameters; train input features and train output label i.e. x_train and y_train
- When this ‘fit’ method is called, then fit and transform both method of Transformers will be called in sequence and input features values will be transformed and pass on to Estimator for model training
Pipeline ‘predict’ method
- Pipeline ‘predict’ method is used for doing a prediction on test data as shown in below code snippet.
- When we call ‘predict’ method, then only Transformer’s ‘transform’ method is getting called

Note: We can save this Pipeline object for future reference purpose as shown in below screenshot.

Flow Diagram of end to end pipeline for my example

Notebook of this exercise is available here.
Thanks for reading this blog … give a clap if you like it 🙂
Источник
Руководство по машинному обучению для начинающих: модель прогноза выживших на «Титанике»
Авторизуйтесь
Руководство по машинному обучению для начинающих: модель прогноза выживших на «Титанике»

Начало работы
Многие другие руководства по машинному обучению рассчитаны на то, что ученик уже является кандидатом наук в области математики или статистики. Настоящее руководство написано для тех, кто раннее не был знаком с машинным обучением.
Формат работы: вы начнёте с введения в машинное обучение на основе написания алгоритма, который будет предсказывать, сколько человек выживет при крушении «Титаника». Затем последуют две тренировочные сессии. Руководство будет направлять вас в дальнейшей работе, но код вы должны будете писать самостоятельно.
Требуемые знания: предполагается, что вы уже имеете опыт работы с Python или знаете его на уровне выше базового. Также предполагается, что вы знакомы с Pandas на базовом уровне. Если вы желаете подтянуть знания по Pandas, предлагаем ознакомиться со специальной статьёй. Также предлагаем вам посмотреть курс по основам Pandas.
Разработка будет выполняться с использованием Ipython (если вы раньше не работали с этой оболочкой, можете посмотреть вводный видеоурок и ознакомиться с командной оболочкой для интерактивных вычислений Jupyter Notebook в нашей статье). По определённым причинам рекомендуется использовать пакет Anaconda с Python 3.
Введение в машинное обучение
В презентации вам дано небольшое задание на проверку логики (чем чаще вы будете уделять время на подобные упражнения, тем лучше вы сможете организовать рабочий процесс). Следует открыть файл titanic_train.csv и определить, какие поля, на ваш взгляд, имеют наибольшее значение для обучения. Вы можете сделать это сейчас, чтобы в середине статьи сравнить свой результат и результат автора.
Машинное обучение с Python
Исходный код, с которым вы будете работать, доступен на платформе Github. Для его загрузки регистрация не требуется. Titanic_Machine_Learning.ipynb — название файла, с которым вам предстоит работать.
Начнём с импорта основных библиотек: Pandas и Numpy.
Для машинного обучения будет использоваться алгоритм Random Forest. На данный момент вам не нужно знать, как он работает (но в будущем обязательно изучите), но вам нужно знать, как его следует применять в деле.
Если вы посмотрели презентацию (что действительно стоило сделать, иначе вы не сможете следовать половине кода), вы знаете, что нужно разделять данные для теста и для тренировки, чтобы не произошло переобучение. Поэтому нужно импортировать функцию train_test_split() .
Теперь давайте отключим предупреждения от Pandas.
Пришло время импортировать функцию joblib . Она будет использоваться для написания модели в файле для повторного использования.
Теперь нужно открыть файл с расширением csv в Pandas. (Вы можете сделать это с помощью Excel или OpenOffice.)

Вы увидите что-то вроде таблицы сверху (обращаем внимание, что некоторые колонки не отображены из-за чрезмерной ширины таблицы).
Sportmaster Lab , Санкт-Петербург, Москва, Краснодар, можно удалённо , От 100 000 до 350 000 ₽
Посмотрите на колонку age. В таблице на изображении выше нет ячеек со значением NaN, что означает, что нет данных. В нашем случае есть просто пустые ячейки. Но обратите внимание, что NaN и пустая ячейка — одно и то же.
В презентации вам было дано задание: нужно было найти полезные, на ваш взгляд, входные данные для алгоритма.
Ожидаемые выходные данные — данные, которые мы получим в колонке survived (выжившие). Как насчёт входных данных?
Вы ведь смотрели фильм «Титаник»? (Если нет, то сейчас будет спойлер: он утонет.) Когда пришло время распределения людей по шлюпкам, больше шансов на спасение имели обладатели билетов первого класса. Также предпочтение отдавалось женщинам и детям.
Таким образом мы можем определить, что наиболее важные моменты, определяющие шанс спасения, это класс билета, возраст и пол.
Если вы женщина солидного возраста с детьми и с билетом первого класса, то вам повезло — вероятность выжить увеличивается.
Если же речь идёт о мужчине среднего возраста с билетом третьего или второго класса, то шансов на выживание становится в разы меньше. Всё как в фильме. Несмотря на то, что в таблице также указана цена билета, нам важнее знать, к какому классу относится этот билет. Если к первому, то шансы на выживание заметно возрастают.
Давайте вернёмся к пустым ячейкам. Мы не можем их оставить пустыми, потому что нам нужна информация в них для выполнения вычислений.
Решение проблемы: заменяем пустые поля медианой.
Перед тем, как продолжить чтение, убедитесь, что вы понимаете следующие термины:
- Среднее арифметическое — сумма чисел вы выборке, делённая на количество чисел в выборке. Пример: вы написали 5 строк кода, ваш друг написал 9 строк кода, ваша подруга написала 7 строк кода. В среднем вы все написали по 7 строк: 5 + 9 + 7 = 21, 21 / 3 = 7.
- Медиана (серединное число) — это такое число выборки, при котором половина значений выборки больше него, а другая половина меньше него. Пример: 1, 2, 5, 10, 21, 33, 57. Медианой в данном случае будет 10, так как числа слева меньше, а числа справа больше и с обеих сторон расположено одинаковое количество чисел.
- Мода — самое повторяющееся число из всех повторяющихся.
В нашем случае сейчас будем использовать медиану для определения возраста.
Можно подсчитать медиану с помощью функции median() в Pandas, из примера выше видно, что медианой является число 29.
Теперь нужно заменить пустые значения в колонке age на значение медианы. Для этого следует использовать функцию fillna() .
Помните пустые (NaN) значения? Теперь они заменены на 29.
Теперь нужно извлечь три нужных нам поля: class (класс), age (возраст), sex (пол).
Для чего это нужно делать?
Это делается для того, чтобы не запутать алгоритм и не создавать лишний шум.
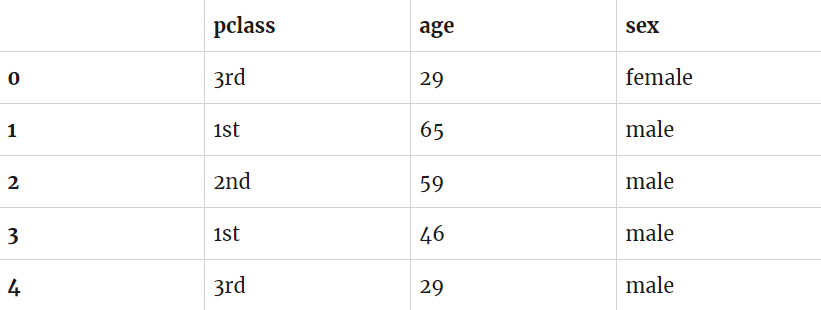
Ожидаемые выходные данные:

Как видите, у нас возникла проблема. Алгоритмы в библиотеке Scikit, которая используется, работают только с числами. Иначе говоря, алгоритм не понимает, что 1st — первый класс.
Давайте исправим проблему. Просто заменим 1st на 1 , 2nd на 2 , 3d на 3 . Элементарно!
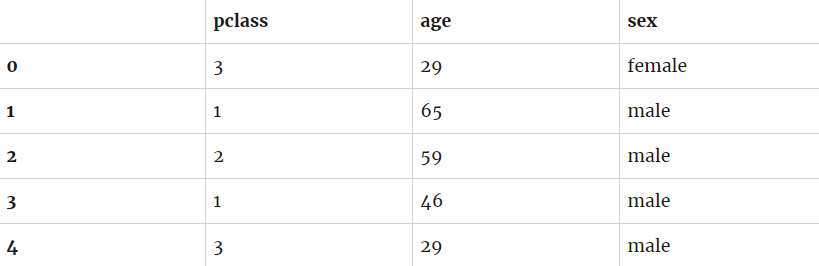
Теперь проблема с классом исправлена. Возраст выставлен правильно. Остаётся поправить проблему с полом.
Будем использовать функцию np.where() , которая не является интуитивной.

Функция заменила female на 0 и male на 1 .
Тестирование для предотвращения переобучения
Как вы могли запомнить из презентации, данные были разделены на набор для тестирования и на набор для обучения. Учебный набор используется для тренировки алгоритма, в то время как набор для теста используется для выявления точности алгоритма. (Так как у нас есть предполагаемые выходные данные, мы можем сравнить их с результатами алгоритма и вычислить процент неточности.)
Пришло время разделить наборы данных. Хотя это и можно сделать вручную, в руководстве это будет выполнено с помощью встроенной функции. Она также будет выполнять другие задачи. Например, перетасовывать данные для нас.
Функция возвращает учебные входные и выходные данные, а также выходной набор данных.
test_size=0.33 значит, что 33% набора данных будет использоваться для тестирования, остальное — для обучения. random_state используется для запуска встроенного генератора случайных выборок.
Давайте выведем несколько значений:
Теперь нужно запустить машинное обучение.
Создаём образец алгоритма Random forest.
Функция fit() используется для обучения нашего алгоритма. Он берёт часть выходных данных и пытается приблизить свой результат к ним. Поэтому мы и сузили поля для сканирования, теперь у алгоритма нет серьёзных помех, которые могли бы быть из-за прочей информации.
В идеале образец алгоритма научится предсказывать количество выживших корабле. Давайте проверим точность алгоритма.
Функция score() работает с тестовыми входными данными и выясняет, насколько точным является прогноз на основе известных выходных тестовых данных.
В примере выше показана точность, которая составила 79%. Мы узнаем, на сколько это хорошо, только когда сможем сравним с чем-нибудь.
Последний шаг близок. Всё это время тренировался алгоритм. Но нам ведь не нужно, чтобы он всё время повторял этот процесс. (Если каждый день складывать одни и те же числа, то умнее человек не станет, верно?) Следующая часть статьи не отнимет у вас много времени, так как наш набор данных невелик.
Мы можем записать модель машинного обучения в файл, чтобы в будущем иметь возможность использовать её повторно.
Раньше для этого использовалась библиотека Pickle, но функция joblib.dump намного проще. Применение compress=9 является необходимым условием, в противном случае будут созданы десятки файлов.
Практика
В этой секции созданный алгоритм машинного обучения будет запущен в новом файле.
Работать предстоит с новым файлом, который раннее не использовался — titanic_test.csv . Он был создан с использованием оригинальных данных, от которых были отсечены 30% данных.
Извлеките из набора данные класса и пола, как мы это сделали для первой практики.
Теперь нужно взять входные данные и пропустить их через прогнозирующую функцию:
Сверху вы видите пустую функцию predict() . Вам нужно сделать predict(data) , чтобы прогнозирование запустить.
На этом урок закончен. Спасибо за внимание!
Источник







