- Получаем всю информацию о текущем URL на JavaScript
- Пример использования window.location.*
- Подходы к извлечению данных из веб-ресурсов
- Анализ DOM дерева
- Парсинг строк
- Регулярные выражения и парсинг XML
- Визуальный подход
- Проблемы и общие рекомендации
- 1.5. HTML-ссылки
- Как сделать гиперссылки на сайте
- 1. Структура ссылки
- 2. Абсолютный и относительный путь
- 2.1. Абсолютный путь
- 2.2. Относительный путь
- 3. Якоря
- 4. Как сделать изображение-ссылку
- 5. Как сделать ссылку на телефонный номер, скайп или адрес электронной почты
Получаем всю информацию о текущем URL на JavaScript
Для написания своих модулей или реализации интересных идей вам могут потребоваться информация о текущем URL и способы получения отдельных его частей.
Сделать это можно с помощью объекта window.location на JavaScript.
В качестве примера рассмотрим ссылку:
А теперь подробно рассмотрим все свойства объекта.
1. window.location.href будет содержать в себе полный URL без изменений. В нашем случае:
2. window.location.protocol будет содержать в себе используемый протокол сайта (https или http) с двоеточием. В нашем случае:
3. window.location.search будет содержать в себе GET параметры (От символа ? включительно до #). В нашем случае:
4. window.location.host будет содержать в себе хост (имя домена) и порт. В нашем случае:
5. window.location.pathname будет содержать в себе относительный адрес страницы. В нашем случае:
6. window.location.hostname будет содержать в себе хост (имя домена) без порта. В нашем случае:
7. window.location.port будет содержать в себе номер порта. В нашем случае:
8. window.location.hash будет содержать в себе указание на конкретный элемент на странице (якорь). В нашем случае:
Пример использования window.location.*
Для примера выведем сообщение, если пользователь находится на главной странице вашего сайта:
С помощью этих 8 свойств вы сможете сделать, например, подсветку активного пункта меню в зависимости от страницы, на которой находится пользователь, или воплотить другие интересные решения.
Источник
Подходы к извлечению данных из веб-ресурсов
В предыдущей статье мы рассмотрели основные понятия и термины в рамках технологии Data Mining. Сегодня более детально остановимся на Web Mining и подходах к извлечению данных из веб-ресурсов.
Web Mining — это процесс извлечения данных из веб-ресурсов, который, как правило, имеет больше практическую составляющую нежели теоретическую. Основная цель Web Mining — это сбор данных (парсинг) с последующим сохранением в нужном формате. Фактически, задача сводится к написанию HTML парсеров, и как раз об этом поговорим более детально.
Есть несколько подходов к извлечению данных:
- Анализ DOM дерева, использование XPath.
- Парсинг строк.
- Использование регулярных выражений.
- XML парсинг.
- Визуальный подход.
Рассмотрим все подходы более детально.
Анализ DOM дерева
Этот подход основывается на анализе DOM дерева. Используя этот подход, данные можно получить напрямую по идентификатору, имени или других атрибутов элемента дерева (таким элементом может служить параграф, таблица, блок и т.д.). Кроме того, если элемент не обозначен каким-либо идентификатором, то к нему можно добраться по некоему уникальному пути, спускаясь вниз по DOM дереву, например:
body -> p[10] -> a[1] -> текст ссылки
или пройтись по коллекции однотипных элементов, например:
body -> links -> 5 элемент -> текст ссылки
Достоинства этого подхода:
- можно получить данные любого типа и любого уровня сложности
- зная расположение элемента, можно получить его значение, прописав путь к нему
Недостатки такого подхода:
- различные HTML / JavaScript движки по-разному генерируют DOM дерево, поэтому нужно привязываться к конкретному движку
- путь элемента может измениться, поэтому, как правило, такие парсеры рассчитаны на кратковременный период сбора данных
- DOM-путь может быть сложный и не всегда однозначный
Этот подход можно использовать вместе с библиотекой Microsoft.mshtml, которая, по сути. является core элементом в Internet Explorer.
Data Extracting SDK использует Microsoft.mshtml для анализа DOM дерева, но является «надстройкой» над библиотекой для удобства работы:
UriHtmlProcessor proc = new UriHtmlProcessor( new Uri ( «http://habrahabr.ru/new/page1/» ));
proc.Initialize();
* This source code was highlighted with Source Code Highlighter .
Следующим эволюционным этапом анализа DOM дерева является использования XPath — т.е. путей, которые широко используются при парсинге XML данных. Суть данного подхода в том, чтобы с помощью некоторого простого синтаксиса описывать путь к элементу без необходимости постепенного движения вниз по DOM дереву. Данный подход использует всеми известная библиотека jQuery и библиотека HtmlAgilityPack:
HtmlDocument doc = new HtmlDocument();
doc.Load( «file.htm» );
foreach (HtmlNode link in doc.DocumentElement.SelectNodes( «//a[@href» ])
<
HtmlAttribute att = link[ «href» ];
att.Value = FixLink(att);
>
doc.Save( «file.htm» );
* This source code was highlighted with Source Code Highlighter .
Парсинг строк
Несмотря на то, что этот подход нельзя применять для написания серьезных парсеров, я о нем немного расскажу.
Иногда данные отображаются с помощью некоторого шаблона (например, таблица характеристик мобильного телефона), когда значения параметров стандартные, а меняются только их значения. В таком случае данные могут быть получены без анализа DOM дерева, а путем парсинга строк, например, как это сделано в Data Extracting SDK:
Компания: Microsoft
Штаб-квартира: Редмонд
» ;
string company = data.GetHtmlString( «Компания: » , «
» );
string location = data.GetHtmlString( «Штаб-квартира: » , «
// output
// company = «Microsoft»
// location = «Редмонт»
* This source code was highlighted with Source Code Highlighter .
Использование набора методов для анализа строк иногда (чаще — простых шаблонных случаях) более эффективный чем анализ DOM дерева или XPath.
Регулярные выражения и парсинг XML
Очень часто видел, когда HTML полностью парсили с помощью регулярных выражений. Это в корне неверный подход, так как таким образом можно получить больше проблем, чем пользы.
Регулярные выражения необходимо использоваться только для извлечения данных, которые имеют строгий формат — электронные адреса, телефоны и т.д., в редких случаях — адреса, шаблонные данные.
Еще одним неэффективным подходом является рассматривать HTML как XML данные. Причина в том, что HTML редко бывает валидным, т.е. таким, что его можно рассматривать как XML данные. Библиотеки, реализовавшие такой подход, больше времени уделяли преобразованию HTML в XML и уже потом непосредственно парсингу данных. Поэтому лучше избегайте этот подход.
Визуальный подход
В данный момент визуальный подход находится на начальной стадии развития. Суть подхода в том, чтобы пользователь мог без использования программного языка или API «настроить» систему для получения нужных данных любой сложности и вложенности. О чем-то похожем (правда применимым в другой области) — методах анализа веб-страниц на уровне информационных блоков, я уже писал. Думаю, что парсеры будущего будут именно визуальными.
Проблемы и общие рекомендации
Проблемы при парсинге HTML данных — использование JavaScript / AJAX / асинхронных загрузок очень усложняют написание парсеров; различные движки для рендеринга HTML могут выдавать разные DOM дерева (кроме того, движки могут иметь баги, которые потом влияют на результаты работы парсеров); большие объемы данных требуют писать распределенные парсеры, что влечет за собой дополнительные затраты на синхронизацию.
Нельзя однозначно выделить подход, который будет 100% применим во всех случаях, поэтому современные библиотеки для парсинга HTML данных, как правило, комбинируют, разные подходы. Например, HtmlAgilityPack позволяет анализировать DOM дерево (использовать XPath), а также с недавних пор поддерживается технология Linq to XML. Data Extracting SDK использует анализ DOM дерева, содержит набор дополнительных методов для парсинга строк, а аткже позволяет использовать технологию Linq для запросов в DOM модели страницы.
На сегодня абсолютным лидером для парсинга HTML данных для дотнетчиков является библиотека HtmlAgilityPack, но ради интереса можно посмотреть и на другие библиотеки.
Источник
1.5. HTML-ссылки

Ссылки можно поделить на две категории:
- ссылки на внешние ресурсы — создаются с помощью элемента
- и используются для расширения возможностей текущего документа при обработке браузером;
- гиперссылки — ссылки на другие ресурсы, которые пользователь может посетить или загрузить.
Как сделать гиперссылки на сайте
1. Структура ссылки
Гиперссылки создаются с помощью элемента . Внутрь помещается текст, который будет отображаться на веб-странице. Текст ссылки отображается в браузере с подчёркиванием, цвет шрифта — синий, при наведении на ссылку курсор мыши меняет вид.
Ссылка состоит из двух частей — указателя и адресной части. Указатель ссылки представляет собой фрагмент текста или изображение, видимые для пользователя. Адресная часть ссылки пользователю не видна, она представляет собой адрес ресурса, к которому необходимо перейти.
Адресная часть ссылки состоит из URl. URl (Uniform Resource Locator) — унифицированный адрес ресурса. При создании адресов для разделения слов между собой рекомендуется использовать дефис, а не символ подчёркивания. В общем виде URl имеющий следующий формат:
Метод доступа, или протокол, осуществляет обмен данными между рабочими станциями в разных сетях. Наиболее распространенные протоколы передачи данных:
file обеспечивает чтение файла с локального диска:
http предоставляет доступ к веб-странице по протоколу HTTP:
https — специальная реализация протокола HTTP, использующая шифрование (как правило, SSL или TLS):
ftp осуществляет запрос к FTP-серверу на получение файла:
mailto запускает сеанс почтовой связи с указанным адресатом и хостом:
Имя сервера описывает полное имя машины в сети, например, site.ru . Если имя сервера не указано, то ссылка считается локальной, т.е. она относится к той же машине, на которой находится HTML-документ, содержащий ссылку.
Номер порта ТСР, на котором функционирует веб-сервер. Представляет собой число, которое необходимо указывать, если метод требует номер порта (отдельные сервера могут иметь свой отличительный номер порта). Если порт не указан, по умолчанию используется порт 80. Стандартными портами являются:
Путь содержит имя папки, в которой находится файл.
2. Абсолютный и относительный путь
Когда в ссылке указывается только имя файла, браузер предполагает, что файл находится в той же папке, что и документ, содержащий гиперссылку. На практике веб-сайты содержат сотни документов, которые размещают в отдельные папки, чтобы ими было легче управлять. Чтобы создать ссылку на файл, находящийся вне папки, содержащей текущий документ, необходимо указать расположение файла или путь. HTML поддерживает два вида пути: абсолютный и относительный.
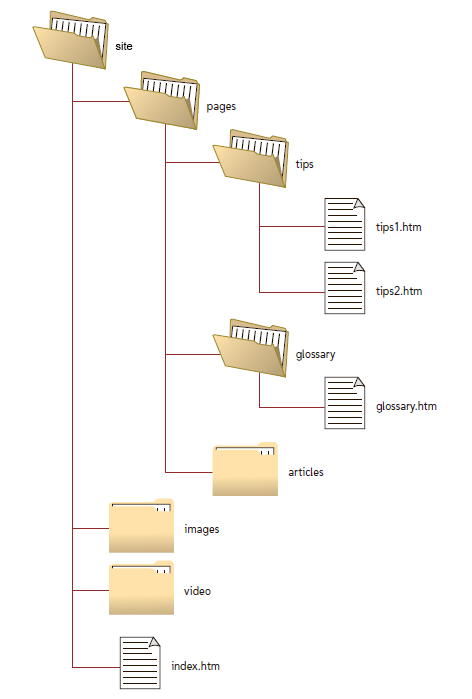 Рис. 1. Пример структуры папок
Рис. 1. Пример структуры папок
2.1. Абсолютный путь
Абсолютный путь указывает точное местоположение файла в пределах всей структуры папок на компьютере (сервере). Абсолютный путь к файлу даёт доступ к файлу со сторонних ресурсов и содержит следующие компоненты:
- протокол, например, http (опционально);
- домен (доменное имя или IP-адрес компьютера);
- папка (имя папки, указывающей путь к файлу);
- файл (имя файла).
Существует два вида записи абсолютного пути — с указанием протокола (полный) и без него:
Когда вы ссылаетесь на страницу на другом сайте, вы можете использовать только полный абсолютный путь.
Если файл находится в корневой папке, то путь к файлу будет следующим:
При отсутствии имени файла будет загружаться веб-страница, которая задана по умолчанию в настройках веб-сервера (так называемый индексный файл).
Обычно в качестве индексного файла выступает документ с именем index.html . Наличие завершающего слеша / означает, что обращение идет к папке, если его нет — напрямую к файлу.
2.2. Относительный путь
Относительный путь описывает путь к указанному документу относительно текущего. Путь определяется с учётом местоположения веб-страницы, на которой находится ссылка. Относительные ссылки используются при создании ссылок на другие документы на одном и том же сайте. Когда браузер не находит в ссылке протокол http:// , он выполняет поиск указанного документа на том же сервере.
Относительный путь содержит следующие компоненты:
- папка (имя папки, указывающей путь к файлу);
- файл (имя файла).
Путь для относительных ссылок имеет три специальных обозначения:
- / указывает на корневую директорию и говорит о том, что нужно начать путь от корневого каталога документов и идти вниз до следующей папки
- ./ указывает на текущую папку
- ../ подняться на одну папку (директорию) выше
Главное отличие относительного пути от абсолютного в том, что относительный путь не содержит имени корневой папки и родительских папок, что делает адрес короче, и в случае переезда с одного домена на другой не нужно прописывать новый абсолютный адрес. Но если сторонний ресурс будет ссылаться например, на ваши изображения с относительными адресами, то они не будут отображаться на другом сайте.
3. Якоря
Якоря, или внутренние ссылки, создают переходы на различные разделы текущей веб-страницы, позволяя быстро перемещаться между разделами. Это оказывается очень удобным в случае, когда на странице слишком много текста. Внутренние ссылки также создаются при помощи элемента с разницей в том, что атрибут href содержит имя указателя — так называемый якорь, а не URl-адрес. Перед именем указателя всегда ставится знак # .
Следующая разметка создаст оглавление с быстрыми переходами на соответствующие разделы:
Если нужно сделать ссылку с одной страницы сайта на определенный раздел другой страницы, то необходимо задать id для этого раздела страницы, а затем добавить его к абсолютному адресу ссылки:
4. Как сделать изображение-ссылку
Чтобы сделать кликабельное изображение, необходимо поместить элемент внутрь элемента . Чтобы ссылка открывалась в другом окне, нужно добавить атрибут target=»_blank» для ссылки.
 Рис. 2. Изображение-ссылка
Рис. 2. Изображение-ссылка
5. Как сделать ссылку на телефонный номер, скайп или адрес электронной почты
У ссылок появились новые возможности — по клику можно не только переходить на другие страницы и скачивать файлы, но и совершать звонки на телефоны, отправлять сообщения или звонить по скайпу.
Источник







