- Описательная статистика с Pandas, SQL и R
- Запускаем PostgreSQL в Docker
- Создание таблицы с данными по оттоку клиентов
- Сортировка
- Извлечение данных
- Группировка данных
- Первые попытки прогнозирования оттока
- Python Pandas — описательная статистика
- пример
- сумма ()
- Ось = 1
- имею в виду()
- станд ()
- Функции и описание
- Обобщающие данные
- Вывести описательные статистики pandas
- Датасет и Pandas для статистического анализа
- Описательная статистика в Pandas
- Проверка на нормальность в Scipy
- Оценка уровня статистической значимости
- Линейная регрессия в Statsmodel
Описательная статистика с Pandas, SQL и R
В этой работе вам предстоит выполнить два домашних задания с открытого курса по машинному обучению от OpenDataScience. Каждое задание нужно выполнить отдельно на Pandas, R и SQL. Первая тема курса посвящена первичному анализу данных с Pandas. Мы рассмотрим этот же пример с использованием SQL и R (решение на R можно найти в нашем репозитории). Чтобы не дублировать исходный текст статьи я оставил только ключевые фразы, поэтому за выводами по полученным результатам следует обращаться именно к нему.
Запускаем PostgreSQL в Docker
В качестве СУБД будем использовать PostgreSQL, которая будет запущена в докер-контейнере. Все данные будут храниться в отдельном дата-контейнере. Подробное описание команд можно найти в статье «Dockerized Postgresql Development Environment».
Подключимся к контейнеру и создадим новую БД:
Создание таблицы с данными по оттоку клиентов
Для взаимодействия с PostgreSQL из Python мы будем использовать драйвер psycopg2 , который можно установить следующей командой:
Перед установкой новых пакетов не забудьте активировать виртуальное окружение.
Теперь скачаем файл с данными, которые потребуются для выполнения примеров:
Создадим таблицу, содержащую данные по оттоку клиентов:
Посмотрим на первые 5 строк:
Посмотрим на распределение данных по целевой переменной churn :
Для более красивого вывода табличных данных можно воспользоваться модулем tabulate . Чтобы установить модуль воспользуйтесь командой pip install tabulate .
Посмотрим на распределение пользователей по переменной area_code . Нормализуем значения, чтобы посмотреть не абсолютные частоты, а относительные:
Сортировка
Упорядочим значения в порядке убывания по столбцу total_day_charge :
Упорядочивать можно по нескольким столбцам:
Извлечение данных
Ответим на вопрос: какова доля людей нелояльных пользователей в нашем датафрейме?
Ответим на вопрос: каковы средние значения числовых признаков среди нелояльных пользователей?
Ответим на вопрос: сколько в среднем в течение дня разговаривают по телефону нелояльные пользователи?
Какова максимальная длина международных звонков среди лояльных пользователей ( churn = FALSE ), не пользующихся услугой международного роуминга ( international_plan = No )?
Для замены значений в колонке можно воспользоваться CASE , например:
Группировка данных
Группирование данных в зависимости от значения признака churn и вывод статистик по трём столбцам в каждой группе:
Примеры с таблицами сопряженности, аналогичными тем, которые рассмотрены в статье, будут показаны далее.
Допустим, мы хотим посмотреть, как наблюдения в нашей выборке распределены в контексте двух признаков: churn и international_plan :
Давайте посмотрим среднее число дневных, вечерних и ночных звонков для разных area_code :
Хотим посчитать общее количество звонков для всех пользователей. Создадим временную таблицу и добавим в нее столбец total_calls :
Первые попытки прогнозирования оттока
Посмотрим, как отток связан с признаком «Подключение международного роуминга» ( international_plan ). Сделаем это с помощью сводной таблицы crosstab:
Далее посмотрим на еще один важный признак – «Число обращений в сервисный центр» ( customer_service_calls ):
Добавим бинарный признак — результат сравнения customer_service_calls > 3 . И еще раз посмотрим, как он связан с оттоком:
Объединим рассмотренные выше условия и построим сводную таблицу для этого объединения и оттока:
Источник
Python Pandas — описательная статистика
Большое количество методов совместно вычисляет описательную статистику и другие связанные операции над DataFrame. Большинство из них являются агрегатами, такими как sum (), mean (), но некоторые из них, например sumsum () , создают объект одинакового размера. Вообще говоря, эти методы принимают аргумент оси , как и ndarray.
DataFrame — «индекс» (ось = 0, по умолчанию), «столбцы» (ось = 1)
DataFrame — «индекс» (ось = 0, по умолчанию), «столбцы» (ось = 1)
Давайте создадим DataFrame и будем использовать этот объект в этой главе для всех операций.
пример
Его вывод выглядит следующим образом —
сумма ()
Возвращает сумму значений для запрошенной оси. По умолчанию ось является индексом (ось = 0).
Его вывод выглядит следующим образом —
Каждый отдельный столбец добавляется индивидуально (строки добавляются).
Ось = 1
Этот синтаксис выдаст вывод, как показано ниже.
Его вывод выглядит следующим образом —
имею в виду()
Возвращает среднее значение
Его вывод выглядит следующим образом —
станд ()
Возвращает стандартное отклонение Бресселя для числовых столбцов.
Его вывод выглядит следующим образом —
Функции и описание
Давайте теперь разберемся с функциями описательной статистики в Python Pandas. В следующей таблице перечислены важные функции —
| Sr.No. | функция | Описание |
|---|---|---|
| 1 | кол-() | Количество ненулевых наблюдений |
| 2 | сумма () | Сумма значений |
| 3 | имею в виду() | Среднее значение |
| 4 | медиана () | Медиана ценностей |
| 5 | Режим() | Режим ценностей |
| 6 | станд () | Стандартное отклонение значений |
| 7 | мин () | Минимальное значение |
| 8 | Максимум() | Максимальное значение |
| 9 | абс () | Абсолютная величина |
| 10 | прод () | Продукт ценностей |
| 11 | cumsum () | Накопительная сумма |
| 12 | cumprod () | Накопительный продукт |
Примечание. Поскольку DataFrame является гетерогенной структурой данных. Общие операции не работают со всеми функциями.
Такие функции, как sum (), cumsum (), работают как с числовыми, так и с символьными (или) строковыми элементами данных без каких-либо ошибок. Хотя на практике агрегации символов обычно не используются, эти функции не выдают никаких исключений.
Такие функции, как abs (), cumprod () выдают исключение, когда DataFrame содержит символьные или строковые данные, поскольку такие операции не могут быть выполнены.
Такие функции, как sum (), cumsum (), работают как с числовыми, так и с символьными (или) строковыми элементами данных без каких-либо ошибок. Хотя на практике агрегации символов обычно не используются, эти функции не выдают никаких исключений.
Такие функции, как abs (), cumprod () выдают исключение, когда DataFrame содержит символьные или строковые данные, поскольку такие операции не могут быть выполнены.
Обобщающие данные
Функция description () вычисляет сводную статистику, относящуюся к столбцам DataFrame.
Его вывод выглядит следующим образом —
Эта функция дает среднее, стандартное и IQR значения. И, функция исключает символьные столбцы и данные о числовых столбцах. «include» — это аргумент, который используется для передачи необходимой информации о том, какие столбцы необходимо учитывать для обобщения. Принимает список значений; по умолчанию «число».
- объект — суммирует строковые столбцы
- число — суммирует числовые столбцы
- all — суммирует все столбцы вместе (не следует передавать его как значение списка)
Теперь используйте следующую инструкцию в программе и проверьте вывод:
Его вывод выглядит следующим образом —
Теперь используйте следующую инструкцию и проверьте вывод —
Его вывод выглядит следующим образом —
Источник
Вывести описательные статистики pandas
Data science не только про обучении ML-моделей. В первую очередь, стоит понять данные: оценить взаимосвязи между переменными, определить их значимость и репрезентативность. Статистика – ключ к раскрытию ваших данных. В этой статье мы поговорим о статистике в Python, какие существуют библиотеки, и как их применять на реальных данных.
Датасет и Pandas для статистического анализа
В качестве анализа возьмем датасет c моллюсками вида abalone, доступный на сайте Kaggle — онлайн-площадке соревнований по машинному обучению. Датасет содержит физические параметры моллюсков: рост, диаметр, высоту, вес раковины и т.д. Также присутствует один категориальный признак — пол моллюска. Ключевым атрибутам является количество колец у моллюска, определяющего его возраст.
Для чтения данных будем использовать pandas. C основами работы pandas вы можете ознакомиться тут.
Первые строчки выглядят следующим образом:
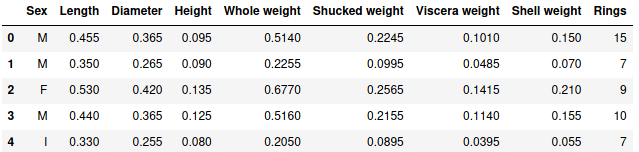 Первые пять строчек DataFrame
Первые пять строчек DataFrame
Описательная статистика в Pandas
Первое, что можно сделать с предоставленными данными, это посмотреть количество наблюдений, среднее, стандартное отклонение, максимальное и минимальное значения. Python-библиотека Pandas включает метод describe , который позволяет взглянуть на описательную статистику числовых данных:
Результатом является соответствующая таблица:
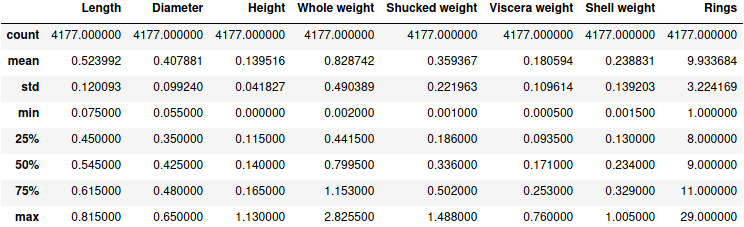 Описательная статистика pandas
Описательная статистика pandas
Проверка на нормальность в Scipy
Нормальный закон распределения является простым и удобным для дальнейшего исследования. Чтобы проверить имеет ли тот или иной атрибут нормальное распределение, можно воспользоваться двумя критериями Python-библиотеки scipy с модулем stats . Модуль scipy.stats поддерживает большой диапазон статистических функций, полный перечень которых представлен в официальной документации.
В основе проверки на “нормальность” лежит проверка гипотез. Нулевая гипотеза – данные распределены нормально, альтернативная гипотеза – данные не имеют нормального распределения.
Проведем первый критерий Шапиро-Уилк [1], возвращающий значение вычисленной статистики и p-значение. В качестве критического значения в большинстве случаев берется 0.05. При p-значении меньше 0.05 мы вынуждены отклонить нулевую гипотезу.
Проверим распределение атрибута Rings, количество колец:
В результате мы получили низкое p-значение и, следовательно, отклоняем нулевую гипотезу:
Второй тест по критерию согласия Пирсона [2], который тоже возвращает соответствующее значение статистики и p-значение:
Этот критерий также отвергает нулевую гипотезу о нормальности распределения колец у моллюсков, так как p-значение меньше 0.05:
Оценка уровня статистической значимости
T-тест (или тест Стьюдента) решает задачу доказательства наличия различий средних значений количественной переменной в случае, когда имеются лишь две сравниваемые группы. Модуль stats Python-библиотеки scipy также предоставляет t-тест. Стоит заметить, проводить t-тест стоит только в случае нормального распределения анализируемых данных. Для экономии времени и места мы опустим эту часть. Здесь имеется функция ttest_ind , вычисляющую t-тест двух независимых выборок. Для зависимых выборок используется функция ttest_rel .
Рассмотрим атрибут Length (длина моллюска). Разделим генеральную совокупность на две выборки и определим гипотезы. Нулевая гипотеза – средние двух выборок равны, альтернативная гипотеза – средние двух выборок не равны. Проведем тестирование:
Результатом является значение t-статистики и p-значение:
Как видим, p-значение больше 0.05, что говорит о верности нулевой гипотезы. Кроме того, необходимо проверить, не превышает ли вычисленная t-статистика табличную. Для этого в качестве доверительного интервала выберем 95%. В модуле stats можно посмотреть табличное значение благодаря функции t.ppf . Она принимает в качестве аргументов соответствующие квартили (с доверительным интервалом 95% они будет равняться 0.975 или 0.025, так как это двусторонний тест) и суммарную степень свободы – сумма степеней свободы выборок.
В результате получили:
что превышает вычисленное значение t-статистики — 1.556. Это означает, что мы не можем отвергнуть нулевую гипотезу. Отсюда заключаем: средние двух выборок равны при условии их нормального распределения.
Линейная регрессия в Statsmodel
Если необходимо оценить связь между двумя атрибутами или более, можно использовать линейную регрессию. Например, с возрастанием одного атрибута увеличивается значение второго или наоборот. Python имеет библиотеку statsmodel, предоставляющую классы и функции для оценки статистических моделей [3].
Линейную регрессию можно построить с помощью метода наименьших квадратов. В statsmodel есть API, который дает возможность писать в R-стиле. Например, рассмотрим Rings, количество колец, и Diamеter, диаметр моллюска:
Метод ols принимает в качестве аргументов формулу для вычислений и DataFrame. summary вернет результат вычисленной модели:
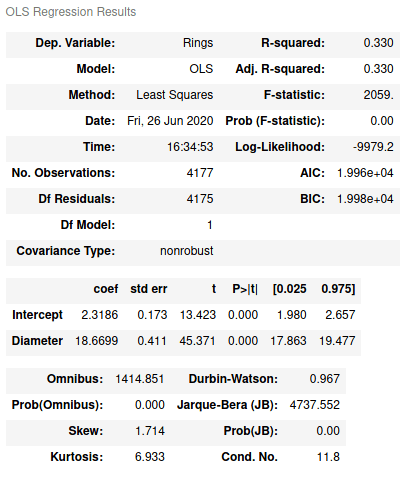 Резюме метода наименьших квадратов
Резюме метода наименьших квадратов
Как видим, здесь имеется широкий перечень статистических критериев: R 2 , F-статистика, коэффициенты линейного уравнения (Intercept и Diameter), степень свободы (Df model) и т.д. Например, R 2 показывает 0.33, что значит только 33 % атрибута Rings может быть объяснено атрибутом Diameter.
Как известно, условием построения линейной регрессии является нормально распределенные остатки [4]. Чтобы получить остатки, используется атрибут resid :
Отметим, что для построения линейной регрессии по двум независимым переменным формула бы выглядела так ‘Rings
Примеры кода выложены на github. В следующей статье мы поговорим об использовании лямбда-функций в Python. А подробные нюансы использования статистических Python-функций и модулей для применения в реальных проектах Data Science вы узнаете на наших курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.
Источник







