- Как вывести повторяющиеся значения в столбце на T-SQL? Microsoft SQL Server
- Исходные данные для примеров
- Выводим повторяющиеся значения в столбце на T-SQL
- Выводим все строки с повторяющимися значениями на T-SQL
- Поиск повторяющихся значений в таблице SQL
- ОТВЕТЫ
- Ответ 1
- Ответ 2
- Ответ 3
- Ответ 4
- Ответ 5
- Ответ 6
- Ответ 7
- Ответ 8
- Ответ 9
- Ответ 10
- Ответ 11
- Ответ 12
- Ответ 13
- Ответ 14
- Ответ 15
- Ответ 16
- Ответ 17
- Ответ 18
- Ответ 19
- Ответ 20
- Ответ 21
- Ответ 22
- Ответ 23
- Ответ 24
- Ответ 25
- Ответ 26
- Ответ 27
- Нахождение повторяющихся значений в таблице в MySQL
- Поиск дубликатов в одном столбце
- Искать дубликаты в нескольких столбцах
- Поиск дубликатов в одной таблице с помощью INNER JOIN
- Поиск дубликатов в нескольких таблицах с помощью INNER JOIN
- Вывод
- Вывести все дубликаты sql
Как вывести повторяющиеся значения в столбце на T-SQL? Microsoft SQL Server
Приветствую всех на сайте Info-Comp.ru! В этой небольшой заметке я покажу, как можно на SQL вывести повторяющиеся значения в столбце таблицы в Microsoft SQL Server. Все будет рассмотрено очень подробно и с примерами.

Исходные данные для примеров
Сначала давайте я расскажу, какие данные я буду использовать в статье, чтобы Вы четко понимали и видели, какие результаты будут возвращаться, если выполнять те или иные действия.
Сразу скажу, что все данные тестовые.
Следующей инструкцией мы создаем таблицу Goods и добавляем в нее несколько строк, в некоторых из которых значение столбца Price будет повторяться.
Останавливаться на том, что делает та или иная инструкция, я не буду, так как это другая тема, если Вам интересно, можете более подробно посмотреть в следующих статьях:
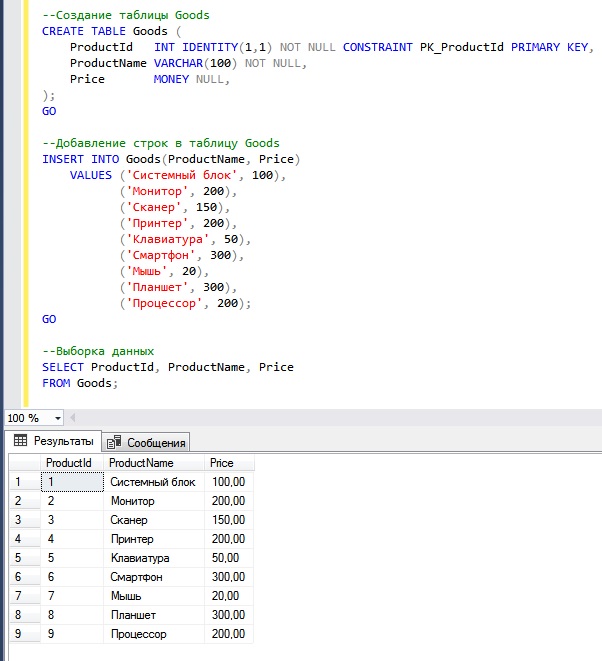
Вы видите, какие данные есть, именно к ним я буду посылать SQL запрос, который будет определять и выводить повторяющиеся значения в столбце Price.
Выводим повторяющиеся значения в столбце на T-SQL
Основной алгоритм определения повторяющихся значений в столбце состоит в том, что нам нужно сгруппировать все строки по столбцу, в котором необходимо найти повторяющиеся значения, и подсчитать количество строк в каждой сгруппированной строке, а затем просто поставить фильтр (>1) на итоговое количество, отбросив тем самым строки со значением 1, т.е. если значение встречается всего один раз, значит, оно не повторяется, и нам не нужно.
Вот пример всего вышесказанного.
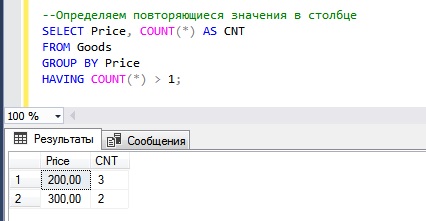
Мы видим, что у нас есть всего два значения, которые повторяются — это 200 и 300. Первое значение, т.е. 200, повторяется 3 раза, второе — 2 раза.
Данные сгруппировали мы конструкцией GROUP BY, подсчитали количество значений встроенной функцией COUNT, а отфильтровали сгруппированные строки конструкцией HAVING.
Выводим все строки с повторяющимися значениями на T-SQL
Но в большинстве случаев просто узнать повторяющиеся в столбце значения недостаточно, иногда необходимо вывести все записи в этой таблице, которые содержат эти повторяющиеся значения.
Это можно реализовать с помощью подзапроса, но использовать подзапрос, в котором будет группировка, не очень удобно, и уж точно неудобочитаемо. Поэтому мне нравится в каких-то подобных случаях использовать CTE (обобщённое табличное выражение) для повышения читабельности кода. Также чтобы сделать результирующий набор данных более наглядным, его можно отсортировать по целевому столбцу, тем самым мы сразу увидим строки с повторяющимися значениями.
Вот пример, в котором мы выводим все строки с повторяющимися значениями в столбце, отсортированные по столбцу Price.
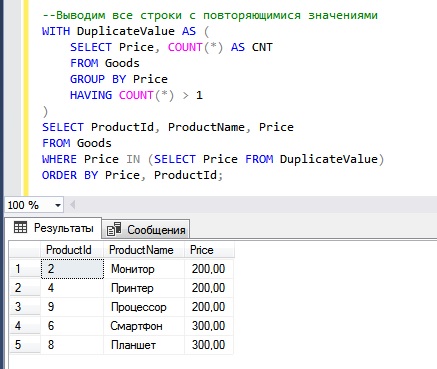
Как видим, сначала у нас идут все строки со значением 200, а затем строки со значением 300. Сортировку мы осуществили конструкцией ORDER BY. Если у Вас возникает вопрос, что такое DuplicateValue, то это всего лишь название CTE выражения, в принципе Вы его можете назвать и по-другому.
Заметка!
Для комплексного изучения языка T-SQL рекомендую почитать мои книги и пройти курсы:
- SQL код – самоучитель по языку SQL для начинающих;
- Стиль программирования на T-SQL – основы правильного написания кода. Книга, направленная на повышение качества T-SQL кода;
- Профессиональные видеокурсы по T-SQL.
У меня на этом все, надеюсь, материал был Вам полезен. Удачи Вам, пока!
Источник
Поиск повторяющихся значений в таблице SQL
Легко найти duplicates с одним полем:
Поэтому, если у нас есть таблица
Этот запрос даст нам Джона, Сэма, Тома, Тома, потому что все они имеют одинаковый email .
Однако я хочу получить дубликаты с тем же email и name .
То есть, я хочу получить «Том», «Том».
Причина, в которой я нуждаюсь в этом: я допустил ошибку и разрешил вставлять повторяющиеся name и значения email . Теперь мне нужно удалить/изменить дубликаты, поэтому мне нужно сначала их найти.
ОТВЕТЫ
Ответ 1
Просто группируйтесь на обоих столбцах.
Примечание: более старый стандарт ANSI должен иметь все неагрегированные столбцы в GROUP BY, но это изменилось с идеей «функциональной зависимости»:
В теории реляционных баз данных функциональная зависимость представляет собой ограничение между двумя наборами атрибутов в отношении из базы данных. Другими словами, функциональная зависимость — это ограничение, которое описывает взаимосвязь между атрибутами в отношении.
- Последние PostgreSQL поддерживает его.
- SQL Server (как на SQL Server 2017) все еще требует наличия всех неагрегированных столбцов в GROUP BY.
- MySQL непредсказуем, и вам нужно sql_mode=only_full_group_by :
- GROUP BY lname ORDER BY показывает неправильные результаты;
- Это наименее затратная совокупная функция при отсутствии ЛЮБОГО() (см. Комментарии в принятом ответе).
- Oracle недостаточно распространен (предупреждение: юмор, я не знаю об Oracle).
Ответ 2
если вы хотите, чтобы идентификаторы дубликатов использовали это:
для удаления дубликатов попробуйте:
Ответ 3
Ответ 4
Если вы хотите удалить дубликаты, здесь гораздо более простой способ сделать это, чем найти четные/нечетные строки в тройной выбор:
И чтобы удалить:
Намного легче читать и понимать IMHO
Примечание. Единственная проблема заключается в том, что вы должны выполнить запрос до тех пор, пока не удалите строки, поскольку каждый раз удаляйте только по 1 каждого дубликата
Ответ 5
Ответ 6
Ответ 7
Немного поздно на вечеринку, но я нашел действительно крутое обходное решение для поиска всех повторяющихся идентификаторов:
Ответ 8
попробуйте этот код
Ответ 9
В случае, если вы работаете с Oracle, этот способ был бы предпочтительнее:
Ответ 10
Это выбирает/удаляет все повторяющиеся записи, кроме одной записи из каждой группы дубликатов. Таким образом, удаление удаляет все уникальные записи + одну запись из каждой группы дубликатов.
Помните о большем количестве записей, это может вызвать проблемы с производительностью.
Ответ 11
Ответ 12
Если вы хотите увидеть, есть ли в вашей таблице повторяющиеся строки, я использовал ниже Query:
Ответ 13
Как мы можем считать дублированные значения? либо он повторяется 2 раза или больше 2. просто считайте их, а не групповыми.
так же просто, как
Ответ 14
Это легкая вещь, которую я придумал. Он использует общее табличное выражение (CTE) и окно раздела (я думаю, что эти функции находятся в SQL 2008 и последующих версиях).
В этом примере найдены все ученики с дублирующимся именем и dob. Поля, которые вы хотите проверить на дублирование, перечислены в предложении OVER. Вы можете включать любые другие поля, которые вы хотите в проекции.
Ответ 15
Ответ 16
SELECT id, COUNT(id) FROM table1 GROUP BY id HAVING COUNT(id)>1;
Я думаю, что это будет работать правильно, чтобы искать повторяющиеся значения в определенном столбце.
Ответ 17
Ответ 18
Используя CTE, мы также можем найти повторяющееся значение
Ответ 19
Это также должно работать, возможно, попробуйте.
Особенно хорошо в вашем случае. Если вы ищете дубликаты, у которых есть префикс или общие изменения, например, например. новый домен в почте. то вы можете использовать replace() в этих столбцах
Ответ 20
Если вы хотите найти повторяющиеся данные (по одному или нескольким критериям) и выбрать фактические строки.
Ответ 21
Ответ 22
SELECT column_name,COUNT(*) FROM TABLE_NAME GROUP BY column1, HAVING COUNT(*) > 1;
Ответ 23
Удалить записи, имена которых повторяются
Ответ 24
Для проверки из дубликата записи в таблице.
Удалить дубликат записи в таблице.
Ответ 25
Мы можем использовать здесь, которые работают с агрегатными функциями, как показано ниже
Здесь в качестве двух полей id_account и data используются Count (*). Таким образом, он выдаст все записи, которые имеют более одного раза одинаковые значения в обоих столбцах.
Мы по какой-то причине ошибочно пропустили добавление каких-либо ограничений в таблицу SQL-сервера, и записи были вставлены дубликаты во все столбцы с интерфейсным приложением. Затем мы можем использовать запрос ниже, чтобы удалить дубликат запроса из таблицы.
Здесь мы взяли все отдельные записи оригинальной таблицы и удалили записи исходной таблицы. Мы снова вставили все различные значения из новой таблицы в исходную таблицу, а затем удалили новую таблицу.
Ответ 26
Удалить записи, имена которых повторяются
УДАЛИТЬ ИЗ CTE ГДЕ T> 1
Ответ 27
Вы можете использовать ключевое слово SELECT DISTINCT, чтобы избавиться от дубликатов. Вы также можете отфильтровать по имени и получить всех с этим именем на столе.
Источник
Нахождение повторяющихся значений в таблице в MySQL
Главное меню » Базы данных » MySQL » Нахождение повторяющихся значений в таблице в MySQL
Для начала у вас должен быть установлен MySQL в вашей системе со своими утилитами: рабочая среда MySQL и клиентская оболочка командной строки. После этого у вас должны быть дубликаты некоторых данных или значений в таблицах базы данных. Давайте рассмотрим это на нескольких примерах. Прежде всего, откройте клиентскую оболочку командной строки с панели задач рабочего стола и введите свой пароль MySQL по запросу.
Мы нашли разные методы поиска дубликатов в таблице. Взгляните на них один за другим.
Поиск дубликатов в одном столбце
Во-первых, вы должны знать синтаксис запроса, используемого для проверки и подсчета дубликатов для одного столбца.
Вот объяснение вышеуказанного запроса:
- Столбец: имя проверяемого столбца.
- COUNT(): функция, используемая для подсчета множества повторяющихся значений.
- GROUP BY: предложение, используемое для группировки всех строк в соответствии с этим конкретным столбцом.
Мы создали новую таблицу под названием «animals» в «data» нашей базы данных MySQL, имеющую повторяющиеся значения. Он имеет шесть столбцов с разными значениями, например, id, Name, Species, Gender, Age и Price, предоставляя информацию о различных домашних животных. После вызова этой таблицы с помощью запроса SELECT мы получаем следующий вывод в нашей клиентской оболочке командной строки MySQL.
Теперь мы попытаемся найти повторяющиеся и повторяющиеся значения из приведенной выше таблицы, используя функцию COUNT и GROUP BY в запросе SELECT. Этот запрос будет считать имена домашних животных, которые встречаются в таблице менее трех раз. После этого он отобразит эти имена, как показано ниже.
Использование того же запроса для получения разных результатов при изменении числа COUNT для имен домашних животных, как показано ниже.
Чтобы получить результаты для 3 повторяющихся значений для имен домашних животных, как показано ниже.
Искать дубликаты в нескольких столбцах
Синтаксис запроса для проверки или подсчета дубликатов для нескольких столбцов следующий:
Вот объяснение вышеуказанного запроса:
- col1, col2: имя проверяемых столбцов.
- COUNT(): функция, используемая для подсчета нескольких повторяющихся значений.
- GROUP BY: предложение, используемое для группировки всех строк в соответствии с этим конкретным столбцом.
Мы использовали ту же таблицу под названием «животные» с повторяющимися значениями. Мы получили приведенный ниже результат, используя указанный выше запрос для проверки повторяющихся значений в нескольких столбцах. Мы проверяли и подсчитывали повторяющиеся значения для столбцов «Gender» и «Price», сгруппированные по столбцу «Price». Он покажет пол домашних животных и их цены, которые находятся в таблице, как дубликаты не более 5.
Поиск дубликатов в одной таблице с помощью INNER JOIN
Вот основной синтаксис для поиска дубликатов в одной таблице:
Вот описание служебного запроса:
- Col: имя столбца, который нужно проверить и выбрать для дублирования.
- Temp: ключевое слово для применения внутреннего соединения к столбцу.
- Таблица: имя проверяемой таблицы.
У нас есть новая таблица order2 с повторяющимися значениями в столбце OrderNo, как показано ниже.
Мы выбираем три столбца: Item, Sales, OrderNo, которые будут отображаться в выводе. В то время как столбец OrderNo используется для проверки дубликатов. Внутреннее соединение выберет значения или строки, имеющие значения элементов более одного в таблице. После выполнения мы получим следующие результаты.
Поиск дубликатов в нескольких таблицах с помощью INNER JOIN
Вот упрощенный синтаксис для поиска дубликатов в нескольких таблицах:
Вот описание служебного запроса:
- col: имя столбцов, которые нужно проверить и выбрать.
- INNER JOIN: функция, используемая для соединения двух таблиц.
- ВКЛ: используется для объединения двух таблиц в соответствии с предоставленными столбцами.
У нас есть две таблицы, «order1» и «order2», в нашей базе данных со столбцом «OrderNo» в обеих, как показано ниже.
Мы будем использовать INNER join для объединения дубликатов двух таблиц в соответствии с указанным столбцом. Предложение INNER JOIN получит все данные из обеих таблиц, объединив их, а предложение ON будет связывать столбцы с одинаковыми именами из обеих таблиц, например, OrderNo.
Чтобы получить определенные столбцы в выходных данных, попробуйте следующую команду:
Вывод
Теперь мы могли искать несколько копий в одной или нескольких таблицах информации MySQL и распознавать функции GROUP BY, COUNT и INNER JOIN. Убедитесь, что вы правильно построили таблицы и что выбраны правильные столбцы.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Источник
Вывести все дубликаты sql
как выбрать все дубликаты талицы SQL запросом ?
что б не число дубликатов а дубликаты все выходили !
НЕ
ИВАНОВ ИВАН ИВАНОВИЧ 2
а так
ИВАНОВ ИВАН ИВАНОВИЧ
ИВАНОВ ИВАН ИВАНОВИЧ
Сделать

 ← →
← →
Ega23 © ( 2009-01-29 11:04 ) [1]
select aName, Count(aName) as Count
from Table
group by aName
having count(aName)>1
← →
Johnmen © ( 2009-01-29 11:05 ) [2]
SELECT T1.F, T1.I, T1.O FROM Table T1
GROUP BY T1.F, T1.I, T1.O
HAVING COUNT(*)>1
← →
Anatoly Podgoretsky © ( 2009-01-29 11:32 ) [3]
> Ega23 (29.01.2009 11:04:01) [1]
Это не даст результата, тут надо громоздить с вложеными запросами.
Ему надо не по одной строчке, как в группирование, а все, но только в том случае если дубли.
Видимо плохо спроектирована таблица, и теперь он пытается удалить лишнее.
← →
Johnmen © ( 2009-01-29 11:34 ) [4]
> Anatoly Podgoretsky © (29.01.09 11:32) [3]
> Ему надо не по одной строчке, как в группирование, а все, но только в том случае если дубли.
Нам он этого не говорил 🙂
> Ему надо не по одной строчке, как в группирование, а все,
> но только в том случае если дубли.
Снимаю шляпу перед твоим телепатором.
← →
Кщд ( 2009-01-29 11:39 ) [6]
>Johnmen © (29.01.09 11:34) [4]
он это ясно сказал: «что б не число дубликатов а дубликаты все выходили !»
да ещё и с примером)
← →
Johnmen © ( 2009-01-29 11:48 ) [7]
> Кщд (29.01.09 11:39) [6]
Что именно он сказал ясно? Дубликаты чего?
← →
Anatoly Podgoretsky © ( 2009-01-29 12:07 ) [8]
> Ega23 (29.01.2009 11:35:05) [5]
Он привел два примера, то чего он не хочет и наоборот.
← →
Роман ( 2009-01-29 12:14 ) [9]
ЕСть таблица допустим 1.dbf
мне нужены к ней запросы по выявлению двойных записей и еще кое что
Вот пробую по разному и ищу тоже везде только одна строка выходит
допустим ИВАНОВ ИВАН ИВАНОВИЧ и количтво например 5
а мне на до чтобы выхолило
ИВАНОВ ИВАН ИВАНОВИЧ
ИВАНОВ ИВАН ИВАНОВИЧ
ИВАНОВ ИВАН ИВАНОВИЧ
ИВАНОВ ИВАН ИВАНОВИЧ
ИВАНОВ ИВАН ИВАНОВИЧ
> [9] Роман (29.01.09 12:14)
Я внесу свою лепту телепатирования.
Подозреваю, что в таблице есть и другие поля, которые НЕ повторяются. Если они тебе нужны и ты их просто не написал в примере, то приведенные запросы не сработают или сработают неправильно. Если других полей нет, то в топку такую таблицу.
← →
Кщд ( 2009-01-29 12:26 ) [11]
>Johnmen © (29.01.09 11:48) [7]
>Что именно он сказал ясно? Дубликаты чего?
дубликаты ФИО (одно это поле или несколько здесь не суть)
и его пример ясно показал, что group by его не устраивает
однако, и ответ (1), и ответ (2) его содержат
и после этого автора обвинили в том, что он «прячет и утаивает»)
не первый раз замечаю такое поведение здесь от уважаемых мной людей(в частности, Вас)
прошу прощения, что вырвалось)
впрочем, это оффтоп — молчу-молчу)
← →
Роман ( 2009-01-29 12:51 ) [12]
← →
Ega23 © ( 2009-01-29 13:02 ) [13]
> мне нужены к ней запросы по выявлению двойных записей
В [1] и [2] тебе ответили.
Если тебя это чем-то не устраивает, то у тебя уже есть начальный инструментарий для дальнейшего наращивания запроса. Например
Select * from Table
where FIO in (см. запрос [2])
И потом, как ты будешь решать, кто из них реальная запись, а кто — дубликат (правда это уже твои проблемы).
> дубликаты ФИО (одно это поле или несколько здесь не суть)
Суть, и очень существенная. Потому что неизвестно, что есть первичный ключ. Потому как если PK не вот это вот самое ФИО, то тогда это никакие не дубликаты а вполне себе самостоятельные сущности.
> и его пример ясно показал, что group by его не устраивает
Ясно только одно, что он чуть-чуть подумать не хочет.
← →
Роман ( 2009-01-29 13:14 ) [14]
>>> В [1] и [2] тебе ответили.
Эти ответы я еще 2 дня назад
мне нужно что бы выполнял другие задачи Если б знал то у МАСТЕРОВ БЫ НЕ СПРАШИВАЛ
> мне нужно что бы выполнял другие задачи Если б знал то
> у МАСТЕРОВ БЫ НЕ СПРАШИВАЛ
Ну ты в своём праве.
← →
Sergey13 © ( 2009-01-29 13:30 ) [16]
> [14] Роман (29.01.09 13:14)
Ну так другие то поля в таблице есть? Они то же повторяются?
← →
Кщд ( 2009-01-29 13:42 ) [17]
>Ega23 © (29.01.09 13:02) [13]
>Суть, и очень существенная. Потому что неизвестно, что есть первичный >ключ. Потому как если PK не вот это вот самое ФИО, то тогда это никакие не >дубликаты а вполне себе самостоятельные сущности.
простите, а какая, собственно, разница «самостоятельная» эта сущность, али нет, если мне необходимо получить дубликаты по полю(или кортежу)? 🙂
>Роман (29.01.09 13:14) [14]
структуру таблицы-то обнажите?
← →
Роман ( 2009-01-29 13:44 ) [18]
Повторяться поля F I O god
Остальные не повторяются rt ft ko se rf guyu fft sss
← →
Кщд ( 2009-01-29 14:02 ) [19]
>Роман (29.01.09 13:44) [18]
см. Ega23 © (29.01.09 13:02) [13]
← →
Кщд ( 2009-01-29 14:04 ) [20]
>Ega23 © (29.01.09 13:02) [13]
>Ясно только одно, что он чуть-чуть подумать не хочет.
человек просто не знает SQL
← →
Ega23 © ( 2009-01-29 14:05 ) [21]
> простите, а какая, собственно, разница «самостоятельная»
> эта сущность, али нет, если мне необходимо получить дубликаты
> по полю(или кортежу)? 🙂
Есть разница. Какая из этих сущностей «главнее»? Какую будем оставлять, а какую — выкидывать?
← →
Ega23 © ( 2009-01-29 14:06 ) [22]
> человек просто не знает SQL
Судя по тому, что он пишет что знает про group by having count>1 .
← →
AndreyV © ( 2009-01-29 14:19 ) [23]
> [21] Ega23 © (29.01.09 14:05)
> Есть разница. Какая из этих сущностей «главнее»? Какую будем
> оставлять, а какую — выкидывать?
Может автор не хочет выкидывать, а делает проверку на предмет визуального контроля ошибок ввода: тёзка или оператор накосячил.
← →
Johnmen © ( 2009-01-29 14:24 ) [24]
> Кщд (29.01.09 12:26) [11]
Мне очень странно твоё возмущение на ровном месте. Ибо автор к моменту поста [6] НИКАКОЙ ясности про дубликаты НЕ ОБОЗНАЧИЛ, как и НЕ ОБОЗНАЧИЛ того, что есть «его пример», и то, что «group by его не устраивает».
← →
Кщд ( 2009-01-29 14:25 ) [25]
>Ega23 © (29.01.09 14:05) [21]
>Какую будем оставлять, а какую — выкидывать?
удаление дубликатов — совсем другой коленкор)
но, как-будто, автор хотел посмотреть, а не удалить.
← →
Ega23 © ( 2009-01-29 14:27 ) [26]
> Может автор не хочет выкидывать, а делает проверку на предмет
> визуального контроля ошибок ввода: тёзка или оператор накосячил.
А как ты это определишь, не зная больше ничего про эту таблицу.
З.Ы. Было дело, делал «Бюро пропусков». В базе было
15000 народу. Повторений по ФИО было ну не то чтобы дофига, но были.
Но люди-то — разные!
← →
Роман ( 2009-01-29 14:28 ) [27]
Абсолютно нет ризницы какие поля если Вы приведете пример с вымышленными полями я и на этом буду благодарен
Мой код SQL такой
select ,count(*) from table group by having count(*) > 1
Для меня он не подходит так как выводит одно повторяющеюся строку и сумму сколько их ,
мне нужно чтоб сколько были столько и выходили
SQL изучаю но еще плохо знаю
← →
AndreyV © ( 2009-01-29 14:29 ) [28]
> [23] AndreyV © (29.01.09 14:19)
Впрочем, какая-то уникальность записи должна быть, иначе действительно в топку такую таблицу.
← →
AndreyV © ( 2009-01-29 14:30 ) [29]
> [26] Ega23 © (29.01.09 14:27)
> А как ты это определишь, не зная больше ничего про эту таблицу.
> Но люди-то — разные!
Уже ответил.
← →
Виталий Панасенко ( 2009-01-29 14:33 ) [30]
select from table where in (
select from table group by having count(*) > 1)
← →
Роман ( 2009-01-29 14:45 ) [31]
Спасибо всем буду пробовать
← →
Кщд ( 2009-01-29 14:49 ) [32]
>AndreyV © (29.01.09 14:29) [28]
>Впрочем, какая-то уникальность записи должна быть, иначе >действительно в топку такую таблицу.
да-да
для поиска дубликатов в табличке без UK и/или PK необходимо её(табличку, то бишь) вначале дропнуть — распространенная практика)
← →
Anatoly Podgoretsky © ( 2009-01-29 15:50 ) [33]
Как обычно вместо объяснения задачи, для чего это нужно, автор обсуждает свое преставление ее решения.
Источник







