- Решение алгоритмических проблем: Поиск повторяющихся элементов в массиве
- Проблема
- Процесс решения задачи
- Brute Force
- Count Iterations
- Sorted Array
- Sum of the Elements
- Marker
- Runner Technique
- Поиск повторений в двумерном массиве, или вычислительная сложность на примере
- Решение алгоритмических проблем: Поиск повторяющихся элементов в массиве
- Проблема
- Процесс решения задачи
- Brute Force
- Count Iterations
- Sorted Array
- Sum of the Elements
- Marker
- Runner Technique
Решение алгоритмических проблем: Поиск повторяющихся элементов в массиве

Nov 2, 2018 · 4 min read

Этот пост является частью серии статей о том, как решать алгоритмические проблемы. Из собственного опыта, я понял, что большинство авторов просто пошагово расписывают решение проблемы. Отсутствие обобщённого представления о проблеме, не позволяет понять её и найти эффективное решение. Исходя из этого понимания, цель данной серии: описывать процессы рассуждений о том, как решать такие проблемы с нуля.
Проблема
Процесс решения задачи
Перед тем как вы увидите решение, давайте немного поговорим о самой проблеме. У нас есть: массив n + 1 элементов с целочисленными переменными в диапазоне от 1 до n .
Например: мас с ив из пяти integers подразумевает, что каждый элемент будет иметь значение от 1 до 4 (включительно). Это автоматически означает, что будет по крайней мере один дубликат.
Единственное исключение — это массив размером 1. Это единственный случай, когда мы получим -1.
Brute Force
Метод Brute Force можно реализовать двумя вложенными циклами:
O(n²) — временная сложность и O(1) — пространственная сложность.
Count Iterations
Другой подход, это иметь структуру данных, в которой можно перечитать количество итераций каждого элемента integer. Такой метод подойдёт как для массивов, так и для хэш-таблиц.
Реализация на Java:
Значение индекса i представляет число итераций i+1 .
Временная сложность этого решения — O(n), но и пространственная — O(n), так как нам требуется дополнительная структура.
Sorted Array
Если мы применяем метод упрощения, то можно попытаться найти решение с отсортированным массивом.
В этом случае, нам нужно сравнить каждый элемент с его соседом справа.
Реализация на Java:
Пространственная сложность O(1), но временная O(n log(n)), так как нам нужно отсортировать коллекцию.
Sum of the Elements
Ещё один способ — это суммирование элементов массива и их сравнение с помощью 1 + 2 + … + n.
В этом примере мы можем добиться результата временной сложности O(n) и пространственной O(1). Тем не менее, это решение работает только в случае, когда мы имеем один дубликат.
Такой способ приведёт в тупик. Но иногда, чтобы найти оптимальное решение, нужно перепробовать всё.
Marker
Кое-что интересное стоит упомянуть. Мы рассматривали решения, не учитывая условия, что диапазон значений integer может быть от 1 до n . Из-за этого примечательного условия каждое значение имеет свой собственный, соответствующий ему индекс в массиве.
Суть этого решения в том, чтобы рассматривать данный массив как список связей. То есть значение индекса указывает на его содержание.
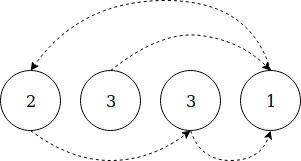
Мы проходим через каждый элемент и помечаем соответствующий индекс, прибавляя к нему знак минус. Элемент является дубликатом, если его индекс уже помечен минусом.
Давайте рассмотрим конкретный пример, шаг за шагом:
Реализация на Java:
Это решение даёт результат временной сложности O(n) и пространственной O(1). Тем не менее, потребуется изменять список ввода.
Runner Technique
Есть ещё один способ, который предполагает рассматривать массив как некий список связей (повторюсь, это возможно благодаря ограничению диапазона значений элементов).
Давайте проанализируем пример [1, 2, 3, 4, 2] :

Такое представление даёт нам понять, что дубликат существует, когда есть цикл. Более того, дубликат проявляется на точке входа цикла (в этом случае, второй элемент).
Мы можем взять за основу алгоритм нахождения цикла по Флойду, тогда мы придём к следующему алгоритму:
- Инициировать два указателя slow и fast
- С каждым шагом: slow смещается на шаг со значением slow = a[slow] , fast смещается на два шага со значением fast = a[a[fast]]
- Когда slow == fast ― мы в цикле.
Можно ли считать этот алгоритм завершённым? Пока нет. Точка входа этого цикла будет обозначать дубликат. Нам нужно сбросить slow и двигать указатели шаг за шагом, пока они снова не станут равны.
Возможная реализация на Java:
Это решение даёт результат временной сложности O(n) и пространственной O(1) и не требует изменения входящего списка.
Источник
Поиск повторений в двумерном массиве, или вычислительная сложность на примере
Доброго времени суток, уважаемое хабрасообщество.
Когда я учился в институте на втором или третьем курсе (то есть, в общем, не так и давно), был у меня, помимо прочих, предмет под названием «алгоритмы и структуры данных». Рассказывали там, однако, не только про сами алгоритмы и структуры, но и о таком понятии, как «вычислительная сложность». Признаюсь, тогда это меня не очень заинтересовало.
«Наверняка заморачиваться с исследованием алгоритма на пространственную и временную сложность нужно только при разработке либо очень высокопроизводительных/высоконагруженных систем, либо при работе с действительно большими объемами данных», — примерно такие мысли посещали меня (да и, наверное, не только меня) тогда.
Однако недавно мне пришлось сильно изменить свое мнение из-за простой, казалось бы, задачи.
Задача представляла собой следующее: имелись Excel таблицы с некоторыми (в основном числовыми) данными. Данные эти, не вдаваясь в подробности, представляли собой идентификаторы, используемые в подсистемах. Требовалось находить в таблицах повторяющиеся значения, и, в зависимости от разных факторов, решать, что с ними делать. На этом этапе у вас уже может появится вопрос: «Почему бы не делать это автоматически?». На самом деле, в таблицы попадали те наборы данных, с которыми автоматизированная система не справилась, и для которых требовалось человеческое вмешательство.
Естественно, перебирать вручную большое количество данных (в среднем порядка 5-10 столбцов и 1000 строк на документ) — занятие неблагодарное, поэтому мной было принято решение немного упростить процесс, хотя бы в плане поиска повторений.
Поскольку написать отдельную утилиту на С было нельзя из-за строгих правил организации, мне пришлось немного почитать про VBA (который я не знал совершенно), и придумать решение в виде VBA-макроса.
Итак, перейдем непосредственно к алгоритмам.
По сути, задача поиска повторений на Excel-листе — это просто задача поиска повторений в двумерном массиве. Но как это сделать? Как ни странно, гугл совершенно не смог мне помочь в решении такой, казалось бы, тривиальной задачи, и пришлось немного пораскинуть мозгами.
Простое решение
Самое простое, прямое и элементарное решение, которое приходит в голову — это просто поэлементное сравнение. На VBA это выглядит примерно так:
Таким образом, мы берем каждую ячейку таблицы, и сравниваем ее со всеми ячейками, которые находятся после нее (стоит отметить, что в том столбце, где вхождение элемента встречается первый раз, повторений быть не может, поэтому мы начинаем сравнение со следующего столбца), и, если находим совпадения, красим их красным цветом. Удобно? Вполне. Однако именно здесь вычислительная сложность показывает зубы. Вот какое время занимает обработка на моей не самой, вроде бы, слабой машине:
- 100 ячеек (10×10) — 70 миллисекунд
- 200 ячеек (10х20) — 240 миллисекунд
- 400 ячеек (10х40) — 920 миллисекунд
- 2000 ячеек (20х100) — 23535 миллисекунд
В целом можно сказать, что при увеличении количества элементов на входе в n раз, время работы увеличится в n 2 раз. Разумеется, такое решение было для меня неприемлемым.
Чуть менее простое решение
Итак, попытаемся немного ускорить наш алгоритм. Первое, что я понял — это то, что операция доступа непосредственно к ячейкам листа занимает огромное количество времени, и количество этих операций нужно попытаться минимизировать. В качестве решения этой проблемы я выбрал первоначальную запись данных из ячеек в память, и работу уже с этой памятью. Для этого нам идеально подойдет двумерный массив.
Для общего же уменьшения количества операций, я решил записывать каждое уникальное значение в отдельный массив, и производить сравнение только с этим массивом уникальных элементов. Выглядит это примерно так:
Итак, мы значительно уменьшили количество операций сравнения элементов за счет сравнения только с уже встреченными уникальными элементами. Также мы сократили количества операций над ячейками в листе до двух (первая — сохранение значения ячейки в массиве, вторая — покраска ячейки). Насколько же уменьшилось время работы?
К сожалению, скорость работы данного алгоритма сильно зависит от энтропии входных данных. Поскольку мы производим сравнение с массивом уникальных элементов, то чем этот массив больше, тем большее время нам понадобится. Иными словами, чем больше во входных данных уникальных элементов, тем медленнее будет работать алгоритм. Я провел два теста для 25000 ячеек ( 5 столбцов и 5000 строк). В первом тесте все ячейки были заполнены одинаковым значением (1), во втором — наоборот, они были заполнены различными значениями без повторений.
Для первого случая работа алгоритма заняла 816 миллисекунд, а для второго — почти 19 секунд. И все же, это значительно быстрее, чем наш первый вариант полного перебора, который смог бы переварить 25000 ячеек за умопомрачительные 58 минут.
Однако стремление к лучшему не знает предела. После некоторых раздумий, я решил не изобретать велосипед, а воспользоваться проверенными алгоритмами. Мой выбор пал на алгоритм быстрой сортировки, имеющий, как известно, сложность O(n log n).
Быстрое решение
Итак, каким же образом можно использовать быструю сортировку для решения поставленной мной задачи?
Помимо самой сортировки, я также добавил обработку выделенной области на листе, ибо так удобнее.
Принцип работы этого алгоритма весьма прост. Мы создаем структуру данных, которая хранит адрес ячейки (номер строки и столбца) и ее значение. Затем из этих структур создается массив, в который заносятся все данные из листа. Массив сортируется быстрой сортировкой.
После этого достаточно пройти по отсортированному массиву один раз, раскрашивая элементы: первый элемент в группе с одинаковыми значениями- зеленым, все остальные — красным.
Стоит заметить, что сам по себе алгоритм быстрой сортировки является неустойчивым, то есть он не сохраняет порядок элементов с одинаковым ключом. Поскольку в нашем случае ключом являлось значение ячейки, то в классическом варианте в каждой группе элементов с одинаковым значением элементы располагались бы в случайном порядке. Очевидно, что мне это не подходит, так как тогда для поиска первого вхождения в таблице нужно было бы еще раз сортировать каждую группу, уже по номеру ячейки. Чтобы избежать этого, я расширил ключ быстрой сортировки, добавив два дополнительных условия для перестановки элементов местеми: теперь в случае совпадения значений элементы будут выстраиваться в том порядке, в котором они встречаются на листе.
Насколько велик был выигрыш в производительности? Лист с 100000 ячеек со случайными значениями данный алгоритм обрабатывает за 4,2 секунды, что, на мой взгляд, является вполне приемлемым результатом.
Итак, какие же выводы можно сделать из всего этого?
- Во-первых, проблема вычислительной сложности алгоритма является актуальной даже для совсе, казалось бы, простых задач, и чтобы столкнуться с ней не обязательно работать с какими-то совсем невероятными объемами данных;
- Во-вторых, не нужно пытаться изобретать велосипед. Во многих случаях лучшим вариантом будет адаптация проверенных классических алгоритмов под конкретную задачу.
Источник
Решение алгоритмических проблем: Поиск повторяющихся элементов в массиве

Проблема
Процесс решения задачи
Перед тем как вы увидите решение, давайте немного поговорим о самой проблеме. У нас есть: массив n + 1 элементов с целочисленными переменными в диапазоне от 1 до n .
Например: массив из пяти integers подразумевает, что каждый элемент будет иметь значение от 1 до 4 (включительно). Это автоматически означает, что будет по крайней мере один дубликат.
Единственное исключение — это массив размером 1. Это единственный случай, когда мы получим -1.
Brute Force
Метод Brute Force можно реализовать двумя вложенными циклами:
O(n²) — временная сложность и O(1) — пространственная сложность.
Count Iterations
Другой подход, это иметь структуру данных, в которой можно перечитать количество итераций каждого элемента integer. Такой метод подойдёт как для массивов, так и для хэш-таблиц.
Реализация на Java:
Значение индекса i представляет число итераций i+1 .
Временная сложность этого решения — O(n), но и пространственная — O(n), так как нам требуется дополнительная структура.
Sorted Array
Если мы применяем метод упрощения, то можно попытаться найти решение с отсортированным массивом.
В этом случае, нам нужно сравнить каждый элемент с его соседом справа.
Реализация на Java:
Пространственная сложность O(1), но временная O(n log(n)), так как нам нужно отсортировать коллекцию.
Sum of the Elements
Ещё один способ — это суммирование элементов массива и их сравнение с помощью 1 + 2 + … + n.
В этом примере мы можем добиться результата временной сложности O(n) и пространственной O(1). Тем не менее, это решение работает только в случае, когда мы имеем один дубликат.
Такой способ приведёт в тупик. Но иногда, чтобы найти оптимальное решение, нужно перепробовать всё.
Marker
Кое-что интересное стоит упомянуть. Мы рассматривали решения, не учитывая условия, что диапазон значений integer может быть от 1 до n . Из-за этого примечательного условия каждое значение имеет свой собственный, соответствующий ему индекс в массиве.
Суть этого решения в том, чтобы рассматривать данный массив как список связей. То есть значение индекса указывает на его содержание.
Мы проходим через каждый элемент и помечаем соответствующий индекс, прибавляя к нему знак минус. Элемент является дубликатом, если его индекс уже помечен минусом.
Давайте рассмотрим конкретный пример, шаг за шагом:
Реализация на Java:
Это решение даёт результат временной сложности O(n) и пространственной O(1). Тем не менее, потребуется изменять список ввода.
Runner Technique
Есть ещё один способ, который предполагает рассматривать массив как некий список связей (повторюсь, это возможно благодаря ограничению диапазона значений элементов).
Давайте проанализируем пример [1, 2, 3, 4, 2] :
Такое представление даёт нам понять, что дубликат существует, когда есть цикл. Более того, дубликат проявляется на точке входа цикла (в этом случае, второй элемент).
Мы можем взять за основу алгоритм нахождения цикла по Флойду, тогда мы придём к следующему алгоритму:
- Инициировать два указателя slow и fast
- С каждым шагом: slow смещается на шаг со значением slow = a[slow] , fast смещается на два шага со значением fast = a[a[fast]]
- Когда slow == fast ― мы в цикле.
Можно ли считать этот алгоритм завершённым? Пока нет. Точка входа этого цикла будет обозначать дубликат. Нам нужно сбросить slow и двигать указатели шаг за шагом, пока они снова не станут равны.
Возможная реализация на Java:
Это решение даёт результат временной сложности O(n) и пространственной O(1) и не требует изменения входящего списка.
Источник







