XSLT первый шаг
1. Введение
Не прошло и трёх лет с тех пор, как у меня зародилась мысль о том, что пора изучать XSLT -))). Мысль зародилась, а везде ещё стоял PHP 4 и зверствовал Salbotron , который, мягко говоря, не отличался высокой производительностью. Да и редко какой браузер мог похвастаться поддержкой этого самого XSLT. По этим соображениям изучение столь перспективного направления я отложил до лучших времён. На данный момент можно смело заявить, что эти времена настали, поскольку вышел PHP 5 с поддержкой XSLT и сносной объектной моделью, а все топовые браузеры уже сами уверенно держат преобразования, только подавай XML. 🙂
Важные ссылки по теме, первоисточники:
- http://w3c.org — комитет по разработке и продвижению стандартов всемирной паутины Internet. На данный момент он является первоисточником практически всех веб-ориентированных стандартов и рекомендаций.
- http://www.w3.org/TR/xml — спецификация расширяемого языка разметки XML, который является основой современного веба. На момент написания статьи доступна пятая редакция версии 1.0, а также вторая редакция версии 1.1.
- http://www.w3.org/TR/xml-names — спецификация использования пространств имён в XML.
- http://www.w3.org/TR/xpath — спецификация по использованию языка поиска частей XML-документа XPath.
- http://www.w3.org/TR/xsl/ — спецификация расширенного языка стилей XSL.
- http://www.w3.org/TR/xslt — спецификация языка преобразований XSLT.
- http://validator.w3.org/ — валидатор HTML.
- http://www.w3.org/TR/xhtml1/ — спецификация XHTML1.0.
Переводы на русский язык:
Для лучшего понимания всего происходящего я рекомендую читать спецификации в следующем порядке:
- XML (это основа!)
- пространства имён (механизм разнородного XML-кода в одном файле)
- XPath (язык выборки элементов из дерева структуры)
- XSLT (преобразования)
- XHTML (то, к чему нужно стремиться)
Особо пытливые могут также уделить внимание расширенному языку стилей XSL.
2. Валидный XHTML
Что такое валидный XHTML? В первую очередь, это XML-документ, который должен соответствовать спецификации XML. Во-вторую, почти обычная HTML-страница, к которой все привыкли.
Почему нужен именно XHTML? Исключительно из соображений совместимости и кросс-браузерности. Страница в XHTML будет с большей вероятностью отображаться корректно в популярных браузерах, чем обычный HTML.
Для рядового клепателя страниц словосочетание XML-документ должно означать следующее:
- Документ содержит объявление XML-документа в самом начале страницы:
- Документ содержит один корневой элемент, в котором находятся все остальные.
- Все элементы (тэги) должны иметь закрывающую часть (
,
).
Также сам XHTML обязывает выполнять следующие условия:
- Документ должен объявлять пространство имён, в рамках которого будут использоваться элементы HTML.
- Документ должен объявлять DOCTYPE перед корневым элементом и указывать в нём один из типов XHTML и соответствующий DTD.
Пример простого документа XHTML1.0:
И так обо всём по порядку.
Объявление XML-документа, в котором указывается его версия и кодировка.
Для большей безопасности кодировку нужно всегда выставлять, иначе могут возникнуть проблемы с невалидными (по отношению к дефолтной кодировке) символами.
Объявление типа документа и его схемы.
Для XHTML 1.0 есть три типа — Strict (строгое соответствие рекомендациям W3C), Transitional (переходный тип) и Frameset (использование фреймов). Для каждого из них предусмотрен отдельный DTD.
Объявление пространства имён и используемого языка.
Очень важно указывать ссылку именно в таком регистре и никак иначе. Это связано с тем, что в XML имена элементов и содержимое их атрибутов регистрозависимы.
Три версии XHTML1.0 предназначены для лучшей обратной совместимости:
- Strict — обеспечивает наибольшее соответствие рекомендациям W3C со стороны браузеров. Однако и сам HTML-код должен следовать этим рекомендациям.
- Transitional — менее строгое соответствие, которое заставляет браузер вести себя так, как если бы это был обычный HTML-документ.
- Frameset — позволяет использовать фреймы.
Помимо XHTML1.0 на данный момент доступен XHTML1.1:
XHTML1.1 по сути является тем же XHTML1.0 Strict и призван вытеснить другие версии XHTML1.0. Однако, по сравнению с XHTML1.0 Strict, у него есть ряд отличий:
- Удалён атрибут lang , его роль выполняет xml:lang . (Модуль [ XHTMLMOD ])
- Для элементов a и map вместо атрибута name нужно использовать атрибут id . (Модуль [ XHTMLMOD ])
- Доступен набор элементов ruby . (Модуль [ RUBY ])
Итак, если вам нужна наибольшая кросс-браузерность и совместимость с рекомендациями W3C, то XHTML1.1 самое оно!
Из этих соображений результатом моих преобразований будет именно XHTML1.1.
3. XSLT-преобразования
Что такое XSLT? Это язык преобразований XML-документа, который был разработан как часть расширенного языка стилей (XSL).
Зачем нужен XSLT? Он позволяет реализовать схему, при которой данные хранятся отдельно, а их представление отдельно. То есть, один XML-документ преобразуется с помощью другого XML-документа (XSL, в котором находятся XSLT-шаблоны) в конечный документ. Результатом может быть XML, HTML или текстовый документ любого формата.
Для того, чтобы воспользоваться XSLT-преобразованиями, в первую очередь нужно сформировать правильный стиль XSL и подключить его к XML-файлу.
Валидным XSL-документом является XML-документ, у которого задано пространство имён xsl и присутствует корневой элемент stylesheet. В самом простом случае стиль может выглядеть, например, так:
Этот стиль не содержит каких-либо явных определений шаблонов или других элементов XSL. Однако, его уже можно использовать. Чтобы посмотреть результат, достаточно сформировать произвольный XML-документ и подключить к нему этот стиль:
За подключение стиля отвечает строка:
Если файлы text.xml и test.xsl созданы и находятся в одной папке, то с помощью любого XSLT-парсера можно преобразовать исходный test.xml в результирующий документ. В качестве парсера могут выступать все популярные браузеры (IE5+, FF2+, Opera9+ и другие), а также модули в языках программирования, например, в PHP. Если вы используете браузер, то достаточно открыть test.xml, и он сразу отобразит примерно такой результат:
При этом кодировка результата будет UTF-8, несмотря на то, что исходный документ был сформирован в windows-1251. К сожалению, браузеры обычно не позволяют просмотреть код результирующего документа, но модуль XSLT в PHP5 даёт возможность передать результирующий код в переменную, которую можно сохранить в файл. Поэтому, используя PHP, я приведу исходный код результирующего документа:
Этот код не является валидным XML-документом и тем более XHTML1.1. Для того, чтобы сформировать нужный код, я усложню исходный XSL-стиль и добавлю туда необходимые шаблоны и преобразования. При этом исходный XML-документ останется без изменений.
В качестве примера я приведу XSL-стиль, который при помощи XSLT будет выводить список атрибутов исходного XML-документа с их значениями, при этом будет формироваться валидный XHTML1.1. Итак, стиль:
Чтобы понять, как он работает, я распишу каждое действие отдельно:
Документ сформирован в кодировке windows-1251, о чём сообщается в атрибуте encoding. Версию XML-документа желательно всегда указывать, это рекомендация W3C.
Затем идёт объявление корневого элемента, стиля:
Обязательным атрибутом является определение пространства имён xsl через атрибут xmlns:xsl= «http://www.w3.org/1999/XSL/Transform» .
Следующим шагом в корневом элементе stylesheet объявляется, каким образом нужно формировать результирующий документ:
- method= «xml» — метод вывода документа. Результирующий документ будет в формате XML.
- encoding= «windows-1251» — кодировка результирующего документа.
- omit-xml-declaration= «no» — пропускать или нет начальное объявление XML-документа ( ). Может иметь значение «yes» или «no» (актуально только для html).
- indent= «yes» — формировать отступы согласно уровню вложенности. Может иметь значение «yes» или «no».
- media-type= «text/xml» — MIME-тип результирующего документа (используется только для метода вывода html).
- doctype-public= «-//W3C//DTD XHTML 1.1//EN» — тип результируюшего документа (DOCTYPE)
- doctype-system= «http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd» — ссылка на DTD
Если метод вывода объявлен html, то значения атрибутов encoding и media-type будут подставлены в заголовок страницы ( . ) посредством метатега.
Объявление основного шаблона:
Именно этот XSLT-шаблон соответствует корню исходного дерева и будет вызван первым для преобразования. Атрибут match принимает значения, которые должны соответствовать языку поиска элементов XPath.
Остальные шаблоны, если таковые имеются, должны подключаться из этого шаблона при помощи средств XSLT.
Формирование XHTML-страницы. Оно начинается с элемента , у которого указано пространство имён xhtml:
Атрибут xmlns= «http://www.w3.org/1999/xhtml» указывает на пространство имён xhtml, которое будет применено по умолчанию к этому элементу и всем дочерним элементам, у которых оно не задано явно.
Атрибут xml:lang= «ru» указывает на язык, в котором сформирована страница (будущая).
Эта часть стиля была нужна для формирования атрибутики валидного XHTML1.1 кода.
Теперь что касается XSLT-преобразований:
Вставка простого текста:
Текст «Мой список:» будет подставлен в тег
Организация цикла по выборке:
Атрибут select принимает выражение XPath, на основе которого делает выборку. Если выборка вернула список узлов, то начинает работать цикл по каждому элементу.
В данном случае выборка вернёт список атрибутов для этого (корневого) и всех дочерних элементов.
В данном случае проверяется на чётность позиция элемента в списке выборки. Если тест возвращает true (порядковый номер элемента чётный), то срабатывает содержимое этого элемента.
Управление атрибутами вышестоящего элемента:
В данном случае, если позиция элемента чётная (определяется вышестоящим if), то в стиль элемента
будет прописан серый цвет фона.
Вывод значений элемента:
Этот код подставит в вышестоящий элемент строку, собранную из имени текущего элемента и его значения. Содержимое атрибута select соответствует XPath.
Вывод ссылки на разработчика парсера XSLT:
Этот небольшой код XSLT формирует ссылку на разработчика парсера XSLT. Во многих случаях она будет разная и содержать разные значения.
Результатом обработки этого стиля ( test.xsl ) станет такой код:
Этот код соответствует стандарту XHTML1.1 и был сформирован на основе исходного XML-документа. Для проверки можно воспользоваться валидатором от W3C, который расположен по адресу http://validator.w3.org/.
В браузере этот код выглядит примерно так:
| IE 6 | FireFox 3 | Opera 9.02 |
|---|---|---|
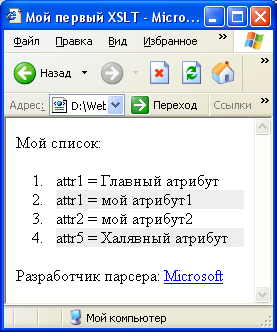 | 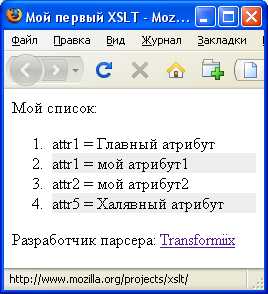 | 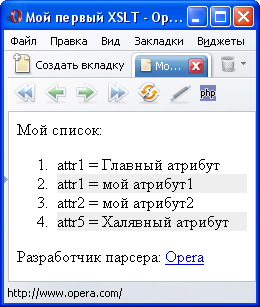 |
4. Приложение
Ссылки на исходный код
Постоянный адрес статьи //anton-pribora.ru/articles/xml/xslt-first-step/. /Автор: Прибора Антон Николаевич, 2009 год/
Использование PHP5 для обработки XSLT
Для получения результирующего документа при помощи PHP5 я использовал такой код:
Дополнительную информацию по использованию XSLT в PHP5 можно найти по адресу http://ru2.php.net/manual/ru/book.xslt.php.
Мысли вслух
«Товарищи, мы стоим на краю огромной пропасти! И я предлагаю сделать большой, решительный шаг вперёд!»
© 2021 Антон Прибора. При копировании материалов с сайта, пожалуйста, указывайте ссылку на источник.
Источник
Использование XSLT для предотвращения XSS путем фильтрации пользовательского контента
Формулировка проблемы
Думаю никому из веб-разработчиков не нужно объяснять что такое XSS и чем он опасен. Но в то же время, многие сайты, такие как форумы, блоги, социальные сети и т.п., стремятся предоставить пользователю возможность вставлять на страницу свой контент. Для удобства неискушенных пользователей изобретаются WYSIWYG-редакторы, делающие процесс добавления красивого комментария легким и приятным. Но за всем этим фасадом скрывается угроза безопасности. Фактически любой WYSIWYG-редактор отправляет на сервер не просто текст комментария, он отправляет HTML-код. И даже если сам редактор не предусматривает использования опасных HTML-тегов (например ), то злоумышленника это не остановит — он может послать на сервер произвольный HTML-текст, который может представлять опастность для других посетителей сайта. Я думаю мало кому понравится получить в свой браузер что-то наподобие:
Таким образом, возникает проблема: полученный от пользователя HTML-код необходимо фильтровать. Но что значить «фильтровать»? Каким должен быть алгоритм фильтрации, чтобы не создавать необоснованных ограничений легальным пользователям, но в то же время сделать невозможной XSS-атаку со стороны злоумышленника? Увы, но HTML достаточно сложен, написать хороший парсер достаточно непросто, а любая ошибка в нем может привести к тому, что у злоумышленника появится лазейка через которую он сможет нанести удар.
Постановка задачи
Для начала я предлагаю сформулировать задачу формально. Итак, что должен сделать фильтр:
- Разобрать полученный HTML
- Применить к нему правила фильтрации, удалить или преобразовать небезопасные элементы
- Вернуть получившийся безопасный HTML для дальнейшей обработки
Для того чтобы разобрать HTML можно воспользоваться существующими библиотеками, например в PHP это можно сделать почти элементарно:
Но что делать с полученным DOM дальше? Как сформулировать какие правила нужно к нему применять? Мне хотелось получить такое решение, которое будет:
- Надежным. Под надежностью я понимаю прежде всего низкую вероятность ошибки в коде, которая может привести к пропуску опасных тегов, атрибутов или значений атрибутов.
- Универсальным. Под универсальностью я понимаю способность фильтровать HTML с произвольной степенью детальности: от «никаких тегов, только текст» до » с атрибутом src, содержащим адрес youtube можно, остальные — нельзя» или «у тегов
атрибут style использовать можно, но из его значений убрать все что относится к свойствам кроме color и background-color»
Поиск решения
Я возвращался к этой задаче время от времени, но удовлетворяющего меня решения не находил. Получалось либо очень сложно (как в настройке, так и в реализации), либо достаточно ограниченно. Решение возникло внезапно. Я обдумывал перспективы использования XSL-шаблонов для форматирования XML-контента, как меня осенило: ведь XSLT используется для трансформации документа, а значит может быть использован и для фильтрации нежелательных элементов тоже!
Решение действительно удовлетворяет сформулированным выше требованиям:
- Надежность. Всю работу выполняет XSLT-процессор, вероятность ошибки в котором достаточно низка, намного ниже чем в самописном решении
- Универсальность. С помощью XSLT можно сформулировать правила фильтрации с любой степенью детальности.
- Легкость конфигурации. Простое конфигурирование сводится к добавлению элементов в «белый» или «черный» список по имеющемуся шаблону. Сложные случаи, конечно, потребуют дополнительных описаний, но эта сложность возникает только если есть необходимость в тонкой настройке фильтрации. Еще одним преимуществом использования XSLT является то, что эта конфигурация может быть прочитана, понята и изменена любым разбирающимся в XSLT специалистом.
Создание фильтра с помощью XSLT
Реализация черного списка
Чтобы выяснить способна ли вообще эта идея функционировать я решил создать XSL-файл, описывающий простое копирование исходного документа в результирующий.
Как можно видеть, вся суть заключается в
Этот фрагмент отвечает за обработку всех элементов документа: тегов и их атрибутов. Текстовые элементы обрабатываются правилом по-умолчанию, которое просто копирует их в результирующий документ. Этим шаблоном обрабатываемый элемент также копируется в результирующий документ, а к его дочерним элементам и атрибутам рекурсивно применяются шаблоны (на самом деле все этот же универсальный шаблон). Таким образом, чтобы отфильтровать некоторые элементы нужно добавить шаблоны для них. Вот так, например, можно отфильтровать теги
Источник







